지난 몇 년간 자동차에 사용되는 자동형 스마트기술이 급성장을 보여 왔는데 이러한 기술들이 무인주행 자동차에 접목되어 더욱 안전한 주행시스템으로 발전하고 있다. 본고에서는 지능형 자동차 시스템과 산업용 머신, 로봇 등에 적용되어 비전 기반 분석을 구동하는 플랫폼에 대하여 알아본다.
글 | 치홍 린(Zhihong Lin), 전략 마케팅 매니저
자가디쉬 산카란(Jagadeesh Sankaran) 박사, 임베디드 비전 엔진 수석 설계자
톰 플래너건(Tom Flanagan), 기술 전략 디렉터
텍사스 인스트루먼트
개요
2013년 9월까지 구글의 셀프 드라이빙 카는 컴퓨터 제어로 단 한 건의 사고 없이 500,000마일 이상을 주행했다[1]. 구글의 파격적인 무인 자동차 프로젝트는 비디오 카메라와 레이더 센서, 레이저 거리측정기를 조합하여(구글의 지도 데이터베이스와 함께) 교통흐름을 보고 운전함으로써 자동차의 안전 및 효율을 개선하는데 그 목적이 있었다. 구글의 무인 자동차 프로토타입에는 아직 상용화 단계에는 이르지 못한 7만 달러의 레이저 레이더 시스템 등 15만 달러의 로봇 부품들이 탑재되어 있다. 2013년 8월, 닛산은 사망률 제로 달성을 목표로 2020년까지 무인 자동차를 선보이겠다는 계획을 발표했다[2]. 셀프 드라이빙 카를 상용화하기 위한 여정은 이 자율 자동차를 보다 저렴하고, 더욱 튼튼하고 안전하게 만드는 방법에 초점이 맞춰질 예정이다. 자율 자동차를 가능하게 하는 핵심 기술 중 하나가 컴퓨터 비전이다. 이것은 신뢰도 높고 저렴한 비전 솔루션을 제공하기 위해 카메라 기반 비전 분석을 이용하고 있다. 카메라 기반 센서가 다른 기술에 비해 저렴하지만, 프로세싱 요건이 크게 증가한다. 오늘날의 시스템은 초당 30 프레임으로 1280×800의 해상도를 처리하고 동시에 5개 이상의 알고리즘을 실행시켜야 할 때가 많다. OMAP5 기술에 기반한 텍사스 인스트루먼트의 최신 애플리케이션 프로세서 TDA2x는 최신 Vision AccelerationPac을 탑재하여 전력 효율과 저렴한 비용, 프로그래머빌리티(programmability), 탄력성을 갖춘 운전보조장치(advanced driver assistance systems, 이하 ADAS)으로 자율 자동차에 20/20 비전을 공급하고 있다. 이 Vision AccelerationPac은 고급 언어로 완전히 프로그래밍이 가능한 특수 하드웨어 유닛과 맞춤형 파이프라인을 가진 프로그래머블 액셀러레이터이다. 이것을 통해 비전 개발자는 표준 프로세서 아키텍처에서는 얻을 수 없는 새로운 차원의 성능을 구현할 수 있다. 고급 언어를 통해 가능해진 Vision AccelerationPac의 프로그래머빌리티 지원은 완성차 제조사들이 다양한 알고리즘 교환을 혁신하고 탐구할 수 있도록 해준다. 이러한 알고리즘들이 아직 완성 단계에 있지는 않지만 출시 속도를 앞당기는데 매우 중요하다는 점을 감안할 때, 이것은 특히 중요한 기능이다.
보는 자동차
미국 통계국의 통계에 따르면, 매년 미국에서는 평균 600만 건의 자동차 사고가 일어난다고 한다. 16-24세 사이의 10대와 청년층의 사망률이 가장 높다. 또한 이 통계에 따르면, 사고의 대부분은 인간의 실수가 원인이라고 한다. 자동차에 비전과 인텔리전스를 넣으면 인간의 실수를 줄이고 교통사고를 줄여 생명을 구할 수 있을 것으로 보인다. 또한 자동차 비전 시스템이 교통정체를 줄이고 도로 수용량을 높이고 연비를 개선하고 매일 출퇴근하는 운전자의 안락함을 향상시키는데 일조를 할 수 있을 것으로 보인다.
ADAS는 완전 자율 자동차로 나아가기 위한 핵심 단계이다. ADAS 시스템에는 적응순항제어(Adaptive Cruise Control), 차선유지지원(Lane Keep Assist), 사각지대탐지(Blind Spot Detection), 차선이탈경고(Lane Departure Warning), 충돌경고시스템(Collision Warning System), 지능형속도관리(Intelligent Speed Adaptation), 교통표지인식(Traffic Sign Recognition), 보행자보호 및 물체감지(Pedestrian Protection and Object Detection), 적응라이트제어(Adaptive Light Control), 자동주차지원시스템(Automatic Parking Assistance systems) 등이 있다.
카메라는 여러 가지 교통 시나리오를 포착하여 저렴하게 지능적 분석을 할 수 있다. 스테레오 프론트 카메라를 적응순항제어에 사용하면 실시간 교통 상황을 포착, 전방 차량과 최적의 거리를 유지할 수 있다. 또한 전방 카메라를 차선유지지원에 사용하여 차량이 계속 차선 중앙에 자리하게 할 수도 있고, 교통표지인식과 물체탐지에 사용할 수도 있다. 사이드 카메라는 교차 교통 감시, 사각지대 탐지, 보행자 인지 등에 사용할 수 있다.
카메라 너머의 분석은 자동차가 시력과 같은 능력을 가지게 해준다. 비디오 카메라 프레임 각각을 분석하여 정확한 정보를 추출한 후 지능적 결정을 내리려면 실시간 비전 분석 엔진이 필요하다. 엄청난 계산 능력이 있어야 찰나의 간격으로 데이터를 처리하여 빠르게 움직이는 자동차를 정확하게 조작할 수 있으며, 넓은 I/O가 있어야 여러 대의 카메라에서 공급되는 비전 분석 엔진 입력 정보로 동시 상호작용을 할 수 있다. 저전력, 낮은 레이턴시, 신뢰성 역시 자동차 비전 시스템의 핵심 요소들이다.
Vision AccelerationPac
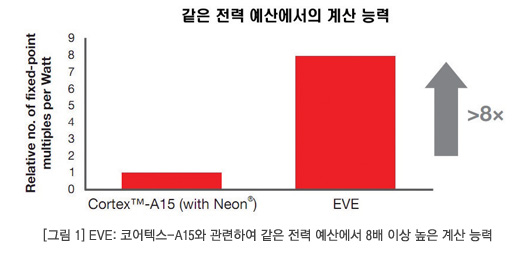
TI의 Vision AccelerationPac은 자동차, 머신 비전, 로봇 등 시장에서 컴퓨터 비전 애플리케이션이 요구하는 처리 능력과 전력, 레이턴시를 가능하게 하기 위해 특별히 고안된 프로그래머블 액셀러레이터이다. 이 Vision AccelerationPac에는 하나 이상의 EVE(Embedded Vision Engines)가 내장되어 있어 프로그래머빌리티와 탄력성과 낮은 레이턴시 처리 능력은 물론 임베디드 비전 시스템을 위한 전력 효율과 작은 실리콘 다이 면적 등을 가능하게 해준다. 그 결과, 성능과 가치의 조합이 탁월하다. 각각의 EVE는 동일한 전력 수준인 경우 기존 ADAS 시스템보다 첨단 비전 분석을 위한 계산 능력에서 8 배 이상 높은 성능을 발휘한다. 자세한 내용은 그림 1을 참고한다. 그림 2는 Vision AccelerationPac 아키텍처를 보여주고 있다.
Vision AccelerationPac 안에는 하나 이상의 EVE가 들어 있고, 32비트애플리케이션 특화 RISC 프로세서(ARP32)와 512비트 벡터 코프로세서(VCOP)를 한 개씩 가지고 있는 비전 최적화 프로세싱 엔진이 빌트인 메커니즘 및 고유의 비전 특화 명령어들과 함께 들어 있어서 동시 프로세싱과 낮은 오버헤드 프로세싱이 가능하다.
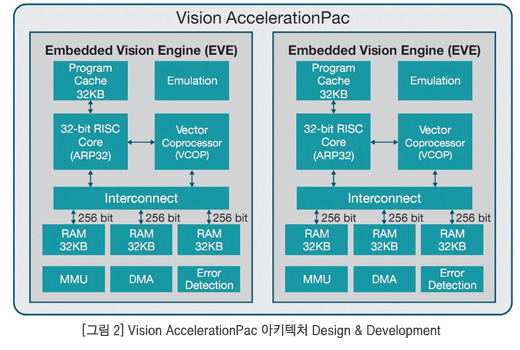
ARP32에는 32 KB의 프로그램 캐시가 들어 있어서 효율적인 프로그램 실행이 가능하다. 또한 여기에 들어 있는 빌트인 에뮬레이션 모듈은 디버깅을 간소화시켜 주며, TI의 Code Composer Studio™ 통합 개발 환경(Integrated Development Environment, IDE)에서 사용할 수 있다.
여기에는 세 개의 병렬 플랫 메모리 인터페이스가 있고, 각각 256비트의 로드 및 스토어 대역폭을 가지고 있어서 총 768비트 너비의 메모리 대역폭이 제공된다(다른 대부분의 프로세서보다 내부 메모리 대역폭이 6배 더 높음). 그리고 총 96 KB의 L1 데이터 메모리를 통해 매우 낮은 프로세싱 레이턴시로 동시 데이터 이동이 가능하다. 또한 각각의 EVE는 로컬 전용 DMA(Direct Memory Access)로 메인 프로세서 메모리와 서로 데이터를 빠르게 주고 받을 수 있고, MMU(Memory Management Unit)로 주소 변환 및 메모리 보호를 할 수 있다. 믿을 수 있는 작동을 위해 각각의 EVE에는 추가적으로 모든 데이터 메모리에 싱글 비트 에러 탐지, 프로그램 메모리에는 더블 비트 에러 탐지가 탑재되어 있다. 주된 아키텍처 특징은 DMA 엔진, 컨트롤 엔진(RISC CPU), 프로세싱 엔진(VCOP)의 완벽한 동시성이다. 이것은 ARP32 RISC CPU로 하여금 인터럽트를 처리하게 하거나 순차 코드를 실행하게 한다. 그 동안 VCOP는 루프를 실행하고 배경에서 다른 루프를 디코딩 하면서, 아키텍처나 메모리 서브시스템의 실속 없이 데이터를 이동시킨다. 또한 이것은 하드웨어 메일박스를 통해 인터 프로세서 통신을 내장 지원하고 있다. EVE는 총 전력 소비가 400 mW에 불과한 최악의 시나리오에서도 8개의 GMAC 프로세싱 능력과 384 Gbps 데이터 대역폭을 가능하게 해주는 가장 전력 효율적인 비전 프로세싱이다.
VCOP 벡터 코프로세서는 빌트인 루프 컨트롤과 어드레스 생성이 가능한 SIMD(Single Instruction Multiple Data) 엔진이다. 이것은 사이클 당 16개의 16비트 멀티플라이어와 함께 듀얼 8웨이 SIMD를 제공함으로써, 관련 로드/스토어와 빌트인 제로 루핑 오버헤드와 라운딩 및 포화에 의해 유지되는 500 MHz 주파수의 일관된 처리량에서 초당 8 GMACS을 달성한다. 이것이 가진 세 가지 소스 작동을 통해 두 개의 벡터 유닛은 추가로 2배를 얻을 수 있으며, 각 사이클마다 32개의 32비트 덧셈을 계산할 수 있다. VCOP 또한 8개의 어드레스 생성 유닛을 가지고 있으며, 각각 4차원 어드레스 능력으로 네 개의 중첩 루프(nested loops)와 세 개의 메모리 인터페이스에 대해 어드레스를 유지할 수 있고, 그로 인해 중첩 루프의 네 가지 레벨에 대해 제로 오버헤드가 가능해진다. 이것은 반복 픽셀 작업에 필요한 계산 사이클을 크게 줄여준다. 벡터 코프로세서는 히스토그램과 가중 히스토그램, 룩업 테이블을 가속할 수 있는 특별한 파이프라인을 가지고 있고, 기울기, 방향, 분류, 비트 인터리빙/디인터리빙/트랜스포징, 통합 이미지, 로컬-바이너리 패턴 등과 같은 공통 컴퓨터-비전 프로세싱 스테이지들을 지원한다. 또한, 벡터 코프로세서는 탄력적이면서 동시적인 로드/스토어 작업이 가능한 특별한 명령어들을 가지고 있어서 디코딩 및 산란/수집 작업의 관심 지역을 가속하여 비접촉 메모리의 데이터를 효율적으로 처리할 수 있다. 이것은 전통적인 이미지 프로세싱 절차에 필요한 전통적인 데이터 이동과 복사를 최소화시킴으로써 초고속 처리 능력을 발휘할 수 있게 해준다. 표준 프로세서 아키텍처에 비해 여러 가지 다양한 기능에서 4~12배의 가속이 일반적이다. VCOP는 태생적으로 산란/수집과 관심 처리 지역을 지원한다. 분류는 목표를 식별하여 추적하거나 고밀도 광학 흐름 검색에서의 매칭 같은 다양한 용도에서 공통적으로 발생하는 컴퓨터 비전 기능이다. EVE는 맞춤형 명령어 지원으로 분류 속도를 크게 높임으로써 EVE가 2048개 32비트 데이터 포인트 어레이를 15.2 μsec 미만으로 분류할 수 있도록 해준다.
Vision AccelerationPac은 TI의 코드 생성 툴 표준 세트를 통해 완벽하게 프로그래밍이 가능하며, 소프트웨어를 PC에서 직접 컴파일, 실행하여 시뮬레이션을 할 수 있다. ARP32 RISC 코어는 TI의 실시간 운영체제 BIOS(RTOS)와 함께 풀 C/C++ 프로그램을 실행할 수 있다. VCOP 벡터 코프로세서는 TI가 VCOP Kernel C라 부르는 것을 통해 생성된 특수 C/C++ 서브세트를 이용해 프로그래밍 된다. VCOP Kernel C는 템플릿화된 C++ 벡터 라이브러리로, 이것은 고급 언어를 통해 기본 하드웨어의 모든 능력을 노출시킨다. VCOP Kernel C로 쓰여진 알고리즘은, 표준 PC나 워크스테이션에서 GNU GCC나 Microsoft짋 MSVC 같은 표준 컴파일러를 이용해 에뮬레이션과 검증이 가능하다. 이렇게 하면 개발자는 벡터화를 구현할 수 있고, 알고리즘 개발 절차 초반에 비트 정확성을 검증할 수 있으며, 광범위한 데이터 세트로 테스트를 하여 알고리즘의 견고함을 확인할 수 있다.
TI의 코드 생성 툴로 소스 코드를 다시 컴파일 하는 방식으로 이 알고리즘을 Vision AccelerationPac에서 바로 실행할 수 있다. VCOP Kernel C로 쓰여진 프로그램은 여러 가지 장점을 가지고 있다. Vision AccelerationPac 아키텍처와 명령어 세트를 활용할 수 있도록 프로그램이 최적화되어 있으며, 특별한 루프 구조를 가지고 있다. 또한 벡터 데이터에서 작동하고, C 서술문과 어셈블리 언어가 거의 일대일 맵핑이다. 따라서 작은 코드 크기와 메모리 풋프린트로도 매우 효율적인 코드가 가능해진다.
Vision AccelerationPac 에서 이용 가능한 프로그래밍 사례는 100 가지가 넘는다. VCOP Kernel C와 비교해 ARM짋NEON짋 SIMD를 이용한 어레이 추가의 사례를 보았을 때, ARM은 6개의 사이클에서 네 개의 32비트 값을 추가하여 출력 당 1.5사이클이라는 내부 루프 성능을 달성한다는 것을 알 수 있다. 그에 반해 VCOP는 768비트의 로드-스토어 대역폭을 충분히 활용하여 한 사이클에서 8개 출력을 달성한다. 이 결과는 출력 당 1/8 사이클 처리량에 필적하는 것으로, 전체 사이클 대 사이클 가속이 ARM에 비해 12배에 달하고 있다.
Vision AccelerationPac 내부에 있는 EVE의 ARP32 RISC 코어는 컨트롤 코드와 순차 프로세싱에 최적화되어 있다. 이것은 TI의 실시간 운영체제인 SYS/BIOS 실행을 지원함으로써 쓰레드, 세마포어, 기타 RTOS 기능들을 지원하고 있다.
EVE는 최적화 컴파일러, TI의 Code Composer Studio IDE에 통합된 시뮬레이터 등 풀 세트 코드 생성 툴들의 지원을 받고 있다. EVE는 하드웨어 카운터를 통한 비침해적 성능 감시 빌트인 지원을 받고 있다. 이를 통해 사용자는 애플리케이션이 실행되는 동안 여러 가지 다양한 성능 신호들을 감시할 수 있고, 애플리케이션의 실시간 성능을 코드 수정 없이 심층 감시할 수 있다.
Vision AccelerationPac을 이용한 원형 교통표지 인식 사례
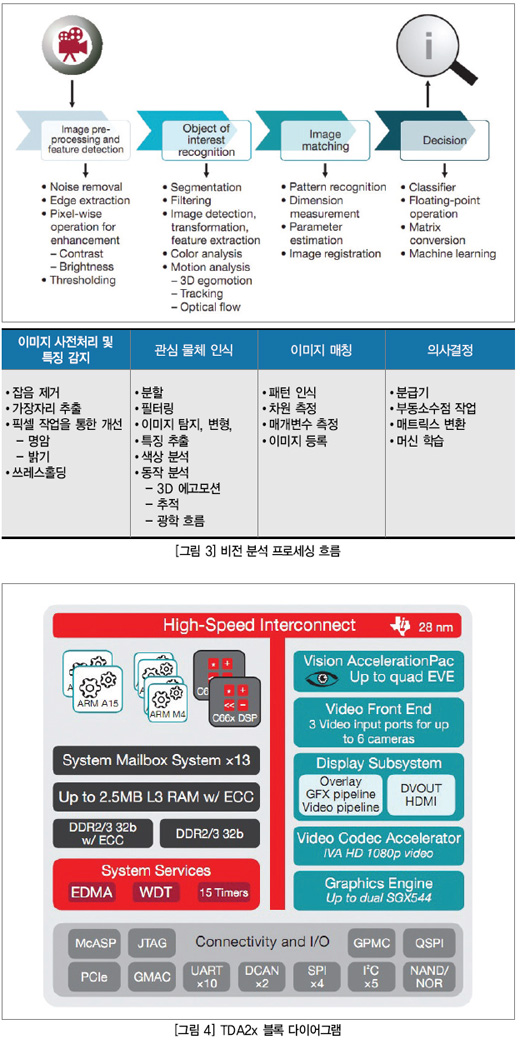
전형적인 비전 분석 프로세싱에는 그림 3처럼 이미지 사전 처리, 특징 감지, 관심 물체 인식, 이미지 및 패턴 매칭, 최종 의사결정 등 여러 가지 단계가 수반된다. Vision AccelerationPac은 비전 분석 프로세싱의 처음 세 단계에서 강도 높은 계산을 덜도록 최적 설계되어 있다. 대개 의사결정에는 분급기(classifier), 부동소수점 작업, 매트릭스 변환 등이 수반되며, 이들은 C66x DSP 코어를 통해 처리될 때 가장 효과적이다. 이 때문에 Vision AccelerationPac는 SoC에서 한 개 이상의 DSP 코어와 짝을 이루고 있다. 그 결과 비전 분석의 작업 부하는 최적 분할된다.
TI의 TDA2x는 저전력 고성능 비전 프로세싱 시스템을 가능하게 해준다. 이것은 두 개의 C66x DSP 코어와 두 개의 EVE(embedded vision engines)을 가진 Vision AccelerationPac을 가지고 있다. 또한 비디오 프론트 엔드와 자동차 접속용 차량 인터페이스도 들어 있다. 그림 4는 이 TDA2xx SoC 블록 다이어그램을 보여주고 있다.
아래는 Vision AccelerationPac이 어떻게 ADAS 원형 교통표지 인식을 가속하는지 설명해주고 있다.
일부 지역에서는 원형 교통표지판의 한 부분에 경계선으로 적색 원이 그려져 있다. 그래서 첫 번째 단계는 YUV422 입력 데이터에서 적색 픽셀만 추출하는 것이다. 그 다음은 밝기와 명암을 이용해 적색 경계선을 확인하는 방식으로 수평 수직 기울기를 계산하는 것이다. 그 다음에는 허프 변환(Hough transform) 알고리즘으로 원 형태를 찾아낸다. 이제 그 원 안에서 확인된 관심 영역의 이미지를 데이터베이스에 저장된 패턴과 비교하여 교통표지판(80 MPH)을 디코딩하면 의사결정 지점에 이르게 된다. 이 경우 내려지는 결정은 속도제한이 시속 80 마일이라는 것이다.
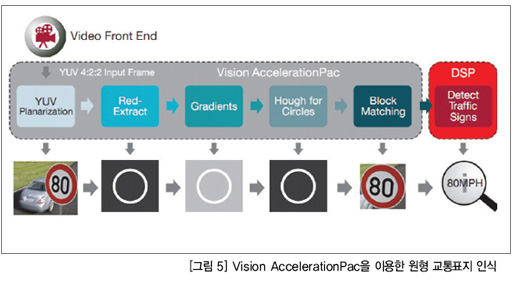
그림 5의 설명처럼, Vision AccelerationPac은 원형 교통표지 인식 사례에서 프로세싱의 대부분을 효율적으로 덜어줄 수 있다. 이 경우에는, 상호비교에 기반한 블록 매칭 템플릿 가속기를 그 예로 들 수 있다. DSP 코어는 최종 의사결정의 확실성을 향상시키는데 사용된다. 허프 변환을 이용하여 원을 찾아내는 일은 매우 계산 집중적인 작업이지만, Vision AccelerationPac을 이용한다면, 원에 관한 허프 변환에는 140 바이트의 코드 공간과 약 (1.88*NUM_RADIUS) +1.81 cyc/pix 사이클의 프로세싱 시간만 있으면 된다. 여기에서 NUM_RADIUS는 허프 공간에서 검색하려는 반경들의 숫자로, 이것은 낮은 전력소비와 비용효과적인 실리콘 다이 면적으로 매우 빠른 비전 인식 시간을 달성할 수 있게 해준다. 초당 30 프레임에서 720 × 480 프레임에 관한 전체 교통표지 인식은 약 50 MHz 또는 EVE 사이클의 10% 미만이다. 충분한 프로세싱 용량이 유지되는 것으로 보아, 하나의 EVE가 동시에 여러 개의 비전 알고리즘을 실행할 수 있음을 알 수 있다.
머신 비전을 위한 Vision AccelerationPac
Vision AccelerationPac이 성능을 발휘할 수 있는 영역은 훨씬 더 많다. 비디오 카메라 분석 프로세싱 외에도, Vision AccelerationPac의 고정소수점 멀티플라이어와 하드웨어 파이프라인은 효율적인 FFT(Fast Fourier Transform) 및 빔 포밍 알고리즘 프로세싱 때문에 레이더 분석 프로세싱에도 이상적이다. Vision AccelerationPac을 이용해 1024 포인트 FFT를 처리하는 데 3.5 μsec도 걸리지 않는다. 따라서 차량 내 카메라 비전 시스템을 보완하는데 레이더를 이용하면 여러 가지 다양한 교통 조건과 기후 조건을 시각화할 수 있다.
차량 내 비전에 사용되는 것과 동일한 메커니즘을 머신 비전에 관한 기타 여러 가지 산업에 응용할 수 있다. 산업 자동화나 비디오 보안 감시 및 경고 시스템, 교통 감시 및 번호판 인식 등이 그 예이다. Vision AccelerationPac을 이용하여 DSP를 증폭하면 오늘날 비전 분석이 가진 문제점들 대다수를 보다 결정론적이고 전력 효율적으로 해결할 수 있다.
결론
Vision AccelerationPac은 텍사스 인스트루먼트의 혁신적인 비전 분석 솔루션이다. 효율적인 임베디드 비전 프로세싱을 위해 고도로 최적화된 탄력적인 SIMD 아키텍처를 가지고 있는 Vision AccelerationPac은 매우 낮은 전력소비와 탁월한 실리콘 다이 면적 효율성을 달성하고 있다. C66x DSP 코어와 함께 사용되는 Vision AccelerationPac은 부동소수점과 매트릭스 계산으로 임베디드 비전 애플리케이션의 전체 프로세싱 체인을 크게 가속시키고 있다. 효율적이고 믿을 수 있는 아키텍처라는 점 외에도, Vision AccelerationPac는 매우 컴팩트한 코드를 출력하는 간단한 C/C++ 기반 프로그래밍 모델을 이용하고 있다. 다시 말해 Vision AccelerationPac이 탑재된 시스템은 매우 낮은 메모리 풋프린트로 비전 시스템 비용과 전력을 낮출 수 있다는 뜻이다. TDA2x SoC과 그 Vision AccelerationPac은 비전 기반 분석을 구동하는 지능형 자동차 시스템과 산업용 머신, “보는” 로봇 등에서 우리의 삶을 향상시키는 이상적인 플랫폼이다. ES
TDA2x SoC에 관한 자세한 내용은 www.ti.com/TDA2x에서 확인할 수 있다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>