



다수의 추가 회로 없이도 리플 자리올림 및 기타 이진 가산기에 비해 훨씬 적은 지연으로 이진 가산을 수행할 수 있는 고속 이진 가산기를 소개한다. 완전히 다른 방식을 사용해 큰 가산기 모듈을 더 작은 모듈로 분할하고 연산을 병렬화함으로써 더 뛰어난 성능을 달성할 수 있다.
글 | 고얄 로히트(Goyal Rohit), 디자인 엔지니어
프리스케일 반도체
이진 가산에 사용하는 기존 가산기 회로는 후속 비트의 가산이 이전 비트의 가산으로 인한 자리올림을 기다리도록 만들었기에, 결과가 다량의 지연과 함께 평가되며, 자리올림 예측 가산기(Carry Look-ahead Adder, CLA)를 사용해 자리올림 리플의 문제를 해소하려면 다수의 추가 게이트(회로)를 사용해 자리올림을 사전 계산해야 하는 리플 자리올림 가산기를 통한 자리올림 리플 방식을 사용해야 한다. 이 글에서는 다수의 추가 회로 없이도 리플 자리올림 및 기타 이진 가산기에 비해 훨씬 적은 지연으로 이진 가산을 수행할 수 있는 고속 이진 가산기를 소개한다.
가산은 모든 대용량 데이터 처리 장치에서 사용하는 기본적인 산술 연산 중 하나이므로 가산 연산의 속도를 높이면 더 빠른 데이터 처리 결과를 얻을 수 있다. 데이터 처리에서 속도에 대한 요구가 계속 증가함에 따라 기본 연산의 속도를 높임으로써 이러한 속도 향상 목표를 달성하고, 더 나아가 코어에 더 뛰어난 아키텍처를 구현할 수 있다. 이 글에서는 이진 가산에 완전히 다른 방식을 사용해 큰 가산기 모듈을 더 작은 모듈로 분할하고 연산을 병렬화함으로써 더 뛰어난 성능을 달성하는 방법에 대해 논의한다.
가산기 모듈을 더 작은 가산기 모듈로 분할하고 증분 방식을 사용함으로써 가산 연산을 병렬화해 모든 모듈의 개별 합산 및 자리올림 단위를 얻은 다음, 이전 블록의 자리올림이 1이면 다음 블록의 결과를 증분하고 그렇지 않으면 동일하게 유지하며, 이 수정 연산은 증분 회로를 사용해 구현할 수 있다. 이에 따라 이전 알고리즘(가산기 회로)에 비해 게이트 레벨 지연이 감소하며 또한 하드웨어도 많이 증가하지 않을 뿐더러 입력 크기가 증가할수록 이 장점은 계속 커지며 회로 복잡성이 입력 크기와 무관하다.
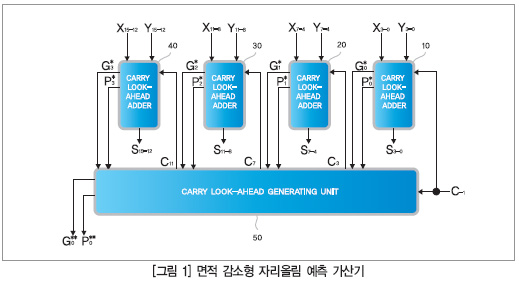
또한 더 작은 CLA모듈로 분할함으로써 하드웨어 요구사항을 완화하고 기존 CLA 가산기가 가진 팬인(fan-in) 문제를 해소하고자 시도했던 다른 회로도 있다. 두 숫자의 16비트 이진 가산에 사용되는 이러한 회로의 최상위 다이어그램이 그림 1에 나와 있다.
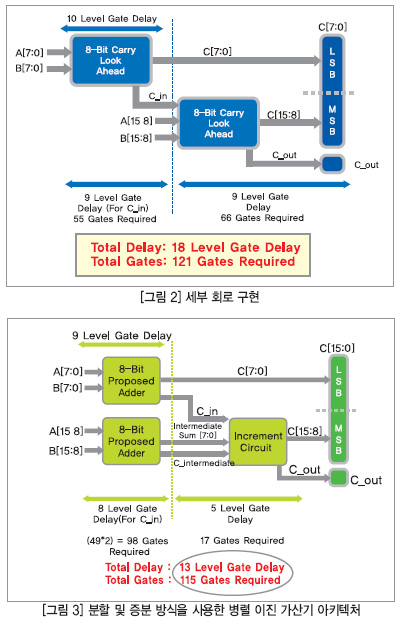
위에 언급된 회로의 상세한 회로 구현 내용이 그림 2에 나와 있다.
세부 회로 구현:
그림 2에 있는 회로에는 각각 8비트 이진 가산이 가능한 블록 2개가 있다(또한 각 블록은 팬인(fan-in) 문제를 해소하고 하드웨어 요구사항을 완화하기 위해 2개의 4비트 CLA 리플 조합으로 구성됨). 여기서 두 번째 블록은 이전 블록에서 전달되는 캐리인(C_in)을 수신할 때까지 작업을 수행할 수 없다. 합산 경로에 대한 입력에는 10 레벨의 게이트 지연이 있는 반면, 캐리아웃(C_in) 경로에 대한 입력에는 9 레벨의 게이트 지연이 있다. 따라서 9 게이트 지연(첫 단계에 대한 지연) 이후 C_in과 같은 16비트 이진 가산이 도래하고, 이어서 섬아웃(sum out) 경로로 자리올림 할 두 번째 블록에 대한 다른 9 레벨 게이트 지연이 이어지면, 이 회로는 16비트 이진수 가산에 대해 18 레벨의 게이트 지연을 처리하며 최대 팬인(fan-in) 제한을 3으로 유지하도록 설계된 경우 이 회로를 구현하려면 총 121개의 게이트가 필요하다. 따라서 이 회로는 순차적으로 작동하며, 다양한 이진 가산 방식을 사용해 병렬화함으로써 성능을 극대화할 수 있다. 그 방법이 다음 절에 설명되어 있다.
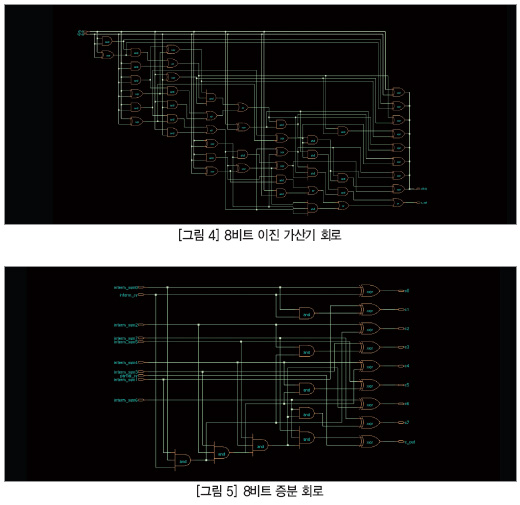
분할 및 증분 방식을 사용한 병렬 이진 가산기 아키텍처:
그림 3에 있는 16비트 이진 가산 회로는 우선 큰 가산기 모듈을 더 작은 8비트 모듈로 분할하고(자세한 구현 방식에 대한 설명은 그림 4 참조), 그 다음 증분 방식을 사용해 각 블록의 가산 연산을 병렬화하는 완전히 다른 이진 가산 방식을 사용한다. 이러한 이진 가산 아키텍처에서 모든 소형 가산기 모듈은 이전 블록에서 입력을 기다리지 않고 병렬로 작동하며, 개별 블록의 결과는 증분 회로를 사용해 나중 단계에서 수정된다(자세한 구현 방식은 그림 5 참조). 즉, 이전 블록의 자리올림이 1 이었다면 결과가 하나씩 증분되며, 그렇지 않으면 결과가 동일하게 유지된다. 그림 3에 나온 것처럼 두 블록은 개별적으로 작동하며, 두 번째 블록의 결과는 나중 단계에서 증분 회로를 사용해 수정된다.
합산 경로에 대한 입력에는 9 레벨의 게이트 지연이 있는 반면, 첫 번째 이진 가산기 블록의 캐리아웃(C_in)에 대한 입력에는 8 레벨의 게이트 지연이 있다. 따라서 16비트 이진 가산의 경우, 8 게이트 지연 이후 C_in이 도래하고, 증분 블록에서 결과를 수정할 다른 5 레벨의 게이트 지연이 이어지면, 이 회로는 16비트 이진수 가산에 대해 13 레벨의 게이트 지연을 처리하며 최대 팬인(fan-in) 제한을 3으로 유지하도록 설계된 경우 이 회로를 구현하려면 총 115개의 게이트가 필요하다. 따라서 이 회로는 병렬로 작동하며 완전히 다른 이진 가산 방식을 사용하므로 게이트 레벨 지연뿐 아니라, 하드웨어 요구사항 측면에서도 획기적인 이점을 얻을 수 있다.
비교 및 결과:
표 1에 나와 있는 것처럼 고속 가산기 회로 솔루션은, 예를 들어 면적 감소형 CLA와 같은 이전 기술과 비교해 게이트 레벨 지연뿐 아니라, 하드웨어 요구사항 측면 모두에서 이점을 제공한다(두 회로 모두 팬인(fan-in) 문제를 해소할 수 있도록 최대 팬인(fan-in) 제한을 3으로 유지하면서 구현됨).
이미 언급한 것과 같이, 이 고속 이진 가산기 회로 솔루션을 사용함으로써 얻을 수 있는 이득은 입력 크기가 증가하면 더욱 커진다. 표 2에서 확인할 수 있다.
결론:
새로운 이진 가산기 회로 솔루션은,
· 위에 언급한 면적 감소형 CLA에 비해 약 1.5배 빠르다(64비트 가산기 회로로 비교할 때).
· 위에 언급한 면적 감소형 CLA에 비해 회로 구현에 필요한 게이트(하드웨어) 수가 적다.
· 최대 3개의 팬인(fan-in)을 사용하므로 높은 핀 밀도 또는 라우팅 혼잡으로 인한 문제가 없다.
· 큰 가산기를 더 작고 간단한 블록으로 분할하는 방식이므로 회로 복잡성이 입력 크기와 무관하다. ES
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



