CEVA, 엣지 AI와 컴퓨팅 겨냥한 고성능 AI/ML 프로세서 아키텍처 공개해
2022-01-13 신윤오 기자, yoshin@elec4.co.kr
3세대 NeuPro AI/ML 아키텍처... 다중의 특화 코프로세서
CEVA는 인공지능 및 머신러닝(AI/ML) 추론 워크로드를 위한 최신 프로세서 아키텍처 NeuPro-M(뉴프로-M)을 발표했다.
NeuPro-M은 광범위한 엣지 AI(Edge AI)와 엣지 컴퓨팅(Edge Compute) 시장을 대상으로 하는 독립적인 이종 아키텍처이다. 심층 신경망의 다양한 워크로드를 동시에 원활하게 처리하는 다중의 특화 코프로세서(co-processor)이자, 설정 변경이 가능한 하드웨어 가속기로 이전 모델 대비 하드웨어의 성능을 5-15배 향상시킨다.
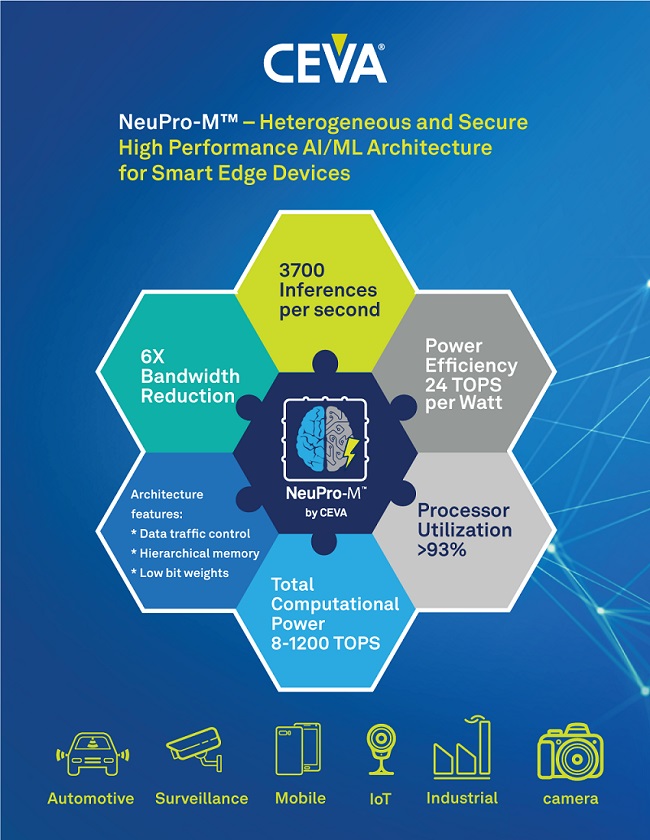
또한 업계 최초로 시스템온칩(SoC)과 이종 시스템온칩(HSoC)의 확장성을 모두 높이고 최대 1,200TOPS(초당 10조회의 연산 속도)에 달하는 성능을 발휘하는 것은 물론, 강력한 보안 부팅 및 엔드 투 엔드(end-to-end) 데이터 개인 정보 보호 옵션을 제공한다.
최첨단 성능을 지닌 단일 NPM11 코어는 ResNet50 신경망(convolutional neural network, CNN)을 처리할 때, 이전 모델에 비해 성능은 5배 향상시키고 메모리 대역폭은 1/6로 감소시켜 와트당 최대 24TOPS의 탁월한 전력 효율을 제공한다.
이전 모델의 뛰어난 성능을 기반으로 설계된 NeuPro-M은 기존의 모든 신경망 아키텍처를 처리한다. 뿐만 아니라, 변압기, 3D 콘볼루션(convolution), 셀프 어텐션(Self-attention) 및 모든 유형의 순환 신경망(recurrent neural networks, RNN)과 같은 차세대 네트워크에 대해 준비가 되어 있으며, 250개 이상의 신경망과 450개 이상의 AI 커널 및 50개 이상의 알고리즘을 처리하는데 최적화되었다.
또한 내장형 벡터 프로세싱 유닛(VPU)은 새로운 신경망 토폴로지와 AI 워크로드의 발전에 대해 미래에 사용 가능한(future proof) 소프트웨어 기반의 지원을 보장한다. 특히 CDNN(CEVA Deep Neural Network) 오프라인 압축 툴은 정확도에 미치는 영향을 최소화하면서 일반적인 벤치마크에 대해 NeuPro-M의 FPS/와트를 5-10배까지 높인다.
"가장 까다로운 AI 워크로드 해결할 수 있어"
CEVA 비전 비즈니스 유닛 부문 부사장이자 제너럴 매니저인 랜 스니르(Ran Snir)는 “점점 더 많은 데이터가 생성되고 센서 기반 소프트웨어 워크로드가 성능과 효율성을 향상시키고자 신경망으로 이동함에 따라, 엣지 AI와 엣지 컴퓨팅에 대한 AI/ML 프로세싱 수요가 빠르게 증가하고 있다. 따라서 우리는 기기에 대한 전력 소모를 증가시키지 않고 점점 더 정교해지는 시스템에서 엣지 AI를 활용할 수 있는 새로운 방법을 찾아야 한다"고 말했다.
그는 이어, "NeuPro-M은 드론에서 보안 카메라, 스마트폰, 오토모티브 시스템에 이르는 수백만 대의 기기에 AI 프로세서와 가속기를 탑재한 자사의 경험을 바탕으로 설계되었다. 혁신적인 분산형 아키텍처와 공유 메모리 시스템 컨트롤러는 대역폭과 지연 시간을 최소화하고 전체 사용률과 전력 효율성을 극대화한다. 또한 시스템온칩과 칩렛(Chiplet)에서 다수의 NeuPro-M 컴플라이언트 코어를 연결해 가장 까다로운 AI 워크로드를 해결할 수 있으므로, 고객은 스마트 엣지 프로세서 설계를 한 단계 더 업그레이드할 수 있게 되었다”라고 말했다.
NeuPro-M 이종 아키텍처는 기능별 코프로세서와 부하 균형 기법(load balancing mechanism)으로 구성되며, 이전 아키텍처 대비 성능과 효율성을 향상시키는 데에 큰 도움을 준다. 먼저 제어 기능을 로컬 컨트롤러에 분산시키고 로컬 메모리 리소스를 계층적 방식으로 실행함으로써 데이터 흐름의 유연성을 높였다.
그 결과, 활용률은 90% 이상을 넘었으며 주어진 시간에 서로 다른 코프로세서와 가속기가 데이터 부족으로부터 안심할 수 있게 되었다. 또한 CDNN 프레임워크에 의해 특정 네트워크, 원하는 대역폭, 사용 가능한 메모리 및 목표 성능에 쓰이는 다양한 데이터 흐름 체계를 실행함으로써 최적의 부하 균형을 달성할 수 있게 되었다.
CEVA는 인공지능 및 머신러닝(AI/ML) 추론 워크로드를 위한 최신 프로세서 아키텍처 NeuPro-M(뉴프로-M)을 발표했다.
NeuPro-M은 광범위한 엣지 AI(Edge AI)와 엣지 컴퓨팅(Edge Compute) 시장을 대상으로 하는 독립적인 이종 아키텍처이다. 심층 신경망의 다양한 워크로드를 동시에 원활하게 처리하는 다중의 특화 코프로세서(co-processor)이자, 설정 변경이 가능한 하드웨어 가속기로 이전 모델 대비 하드웨어의 성능을 5-15배 향상시킨다.
또한 업계 최초로 시스템온칩(SoC)과 이종 시스템온칩(HSoC)의 확장성을 모두 높이고 최대 1,200TOPS(초당 10조회의 연산 속도)에 달하는 성능을 발휘하는 것은 물론, 강력한 보안 부팅 및 엔드 투 엔드(end-to-end) 데이터 개인 정보 보호 옵션을 제공한다.
최첨단 성능을 지닌 단일 NPM11 코어는 ResNet50 신경망(convolutional neural network, CNN)을 처리할 때, 이전 모델에 비해 성능은 5배 향상시키고 메모리 대역폭은 1/6로 감소시켜 와트당 최대 24TOPS의 탁월한 전력 효율을 제공한다.
이전 모델의 뛰어난 성능을 기반으로 설계된 NeuPro-M은 기존의 모든 신경망 아키텍처를 처리한다. 뿐만 아니라, 변압기, 3D 콘볼루션(convolution), 셀프 어텐션(Self-attention) 및 모든 유형의 순환 신경망(recurrent neural networks, RNN)과 같은 차세대 네트워크에 대해 준비가 되어 있으며, 250개 이상의 신경망과 450개 이상의 AI 커널 및 50개 이상의 알고리즘을 처리하는데 최적화되었다.
또한 내장형 벡터 프로세싱 유닛(VPU)은 새로운 신경망 토폴로지와 AI 워크로드의 발전에 대해 미래에 사용 가능한(future proof) 소프트웨어 기반의 지원을 보장한다. 특히 CDNN(CEVA Deep Neural Network) 오프라인 압축 툴은 정확도에 미치는 영향을 최소화하면서 일반적인 벤치마크에 대해 NeuPro-M의 FPS/와트를 5-10배까지 높인다.
"가장 까다로운 AI 워크로드 해결할 수 있어"
CEVA 비전 비즈니스 유닛 부문 부사장이자 제너럴 매니저인 랜 스니르(Ran Snir)는 “점점 더 많은 데이터가 생성되고 센서 기반 소프트웨어 워크로드가 성능과 효율성을 향상시키고자 신경망으로 이동함에 따라, 엣지 AI와 엣지 컴퓨팅에 대한 AI/ML 프로세싱 수요가 빠르게 증가하고 있다. 따라서 우리는 기기에 대한 전력 소모를 증가시키지 않고 점점 더 정교해지는 시스템에서 엣지 AI를 활용할 수 있는 새로운 방법을 찾아야 한다"고 말했다.
그는 이어, "NeuPro-M은 드론에서 보안 카메라, 스마트폰, 오토모티브 시스템에 이르는 수백만 대의 기기에 AI 프로세서와 가속기를 탑재한 자사의 경험을 바탕으로 설계되었다. 혁신적인 분산형 아키텍처와 공유 메모리 시스템 컨트롤러는 대역폭과 지연 시간을 최소화하고 전체 사용률과 전력 효율성을 극대화한다. 또한 시스템온칩과 칩렛(Chiplet)에서 다수의 NeuPro-M 컴플라이언트 코어를 연결해 가장 까다로운 AI 워크로드를 해결할 수 있으므로, 고객은 스마트 엣지 프로세서 설계를 한 단계 더 업그레이드할 수 있게 되었다”라고 말했다.
NeuPro-M 이종 아키텍처는 기능별 코프로세서와 부하 균형 기법(load balancing mechanism)으로 구성되며, 이전 아키텍처 대비 성능과 효율성을 향상시키는 데에 큰 도움을 준다. 먼저 제어 기능을 로컬 컨트롤러에 분산시키고 로컬 메모리 리소스를 계층적 방식으로 실행함으로써 데이터 흐름의 유연성을 높였다.
그 결과, 활용률은 90% 이상을 넘었으며 주어진 시간에 서로 다른 코프로세서와 가속기가 데이터 부족으로부터 안심할 수 있게 되었다. 또한 CDNN 프레임워크에 의해 특정 네트워크, 원하는 대역폭, 사용 가능한 메모리 및 목표 성능에 쓰이는 다양한 데이터 흐름 체계를 실행함으로써 최적의 부하 균형을 달성할 수 있게 되었다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>
100자평 쓰기











