루미너리북스, 맞춤법 넘어 사실 검증까지 자동 수행...RAG 기반 지식 검증·멀티 에이전트 구조로 출판 품질 패러다임 전환
루미너리북스(Luminary Books)는 RAG(검색 증강 생성) 기반 지식 검증 엔진과 멀티 에이전트 협업 시스템을 결합한 국내 최초의 AI 자동 교정·검수 시스템을 공개했다고 밝혔다.
기존 AI 교정 도구가 맞춤법·띄어쓰기 등 단순 문법 오류 교정에 머물렀던 것과 달리, 이 시스템은 원고 속 사실관계의 진위 여부까지 자동으로 검증하는 것이 핵심이다. 도서 한 권 분량의 원고를 30분 이내에 완전 검수하며, 자체 평가 결과 사실검증(팩트체크) 정확도 99.6%를 달성했다. 루미너리북스는 지난 2월부터 자사가 출판하는 모든 도서에 이 시스템을 실제 적용해 운영하고 있다고 업체 측은 밝혔다.
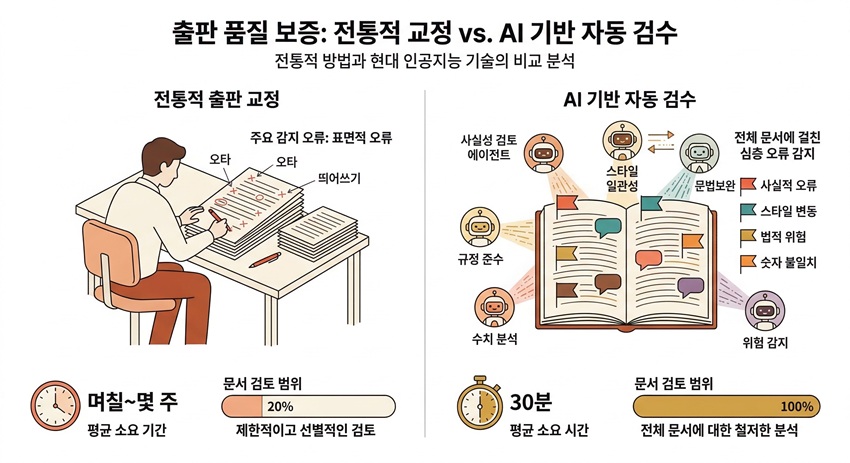
시중의 AI 교정 도구 대부분은 맞춤법, 띄어쓰기, 조사 오류 등 표층적 문법 검사에 한정된다. 역사서에 잘못된 연도가 적혀 있거나, 과학 교양서에 부정확한 수치가 인용돼 있더라도 기존 도구로는 이를 잡아낼 방법이 없었다. 루미너리북스의 시스템은 이러한 한계를 넘어, 사실의 진위를 직접 검증하는 기능을 수행한다는 설명이다.
업체 측에 따르면, 시스템은 원고의 모든 문장에서 사실적 검증이 필요한 내용을 자동으로 추출한 뒤, 수백만 건의 검증된 지식 소스(학술 논문, 백과사전, 공인 통계)를 벡터 데이터베이스로 밀리초 단위로 검색해 근거를 대조한다. 단순 키워드 매칭이 아닌 문맥적 의미 대조(Semantic Comparison) 방식을 적용해 미묘한 사실 오류까지 포착하며, 각 내용에 0~100점의 신뢰도 점수를 부여한다. 신뢰도 70점 미만 항목은 자동으로 플래깅돼 수정 제안과 근거 출처가 리포트에 첨부된다. 맞춤법·문법·띄어쓰기 교정은 물론, 문장에 담긴 사실의 정확성까지 함께 검증하는 것이 특징이다.
루미너리북스의 검수 시스템은 OpenAI의 최신 모델 GPT-5.4 Pro를 베이스 엔진으로 채택했다. GPT-5.4 Pro는 박사급 과학 문제 벤치마크(GPQA Diamond)에서 94.4%의 정확도를 기록해 해당 분야 박사 학위 보유자(69.7%)를 24.7%p 상회했으며, 44개 전문 직종 업무 평가(GDPval)에서도 현직 전문가의 83%를 능가한 프론티어 AI 모델이다.
이 모델 위에 자체 개발한 7개 전문 AI 에이전트를 병렬로 배치한 것이 특징이다. 팩트체커(사실관계 검증), 그래머리안(맞춤법·문법), 스타일리스트(문체 분석), 컨시스턴시(용어 통일), 데이터가드(수치 검증), 컴플라이어(법적 리스크), 오케스트레이터(최종 판정)로 구성된 멀티 에이전트 시스템은 각 분야 석박사급 전문가 7명이 동시에 원고를 교차 검증하는 것과 유사한 수준의 검수 품질을 제공한다는 설명이다.
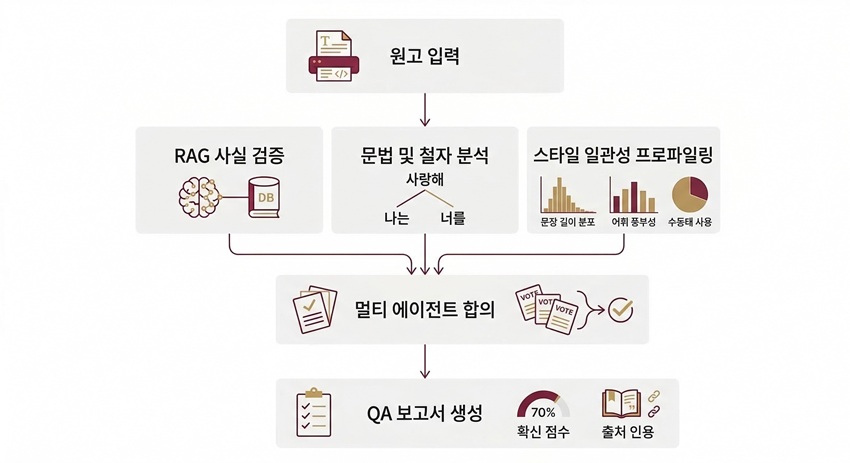
각 에이전트는 독립적으로 검수를 수행한 뒤 합의 알고리즘을 통해 결과를 교차 대조하며, 다수결 투표와 신뢰도 가중 방식을 결합해 오탐(false positive)을 최소화한다.
루미너리북스는 시스템의 신뢰성을 입증하기 위해 역사서, 자기계발서, 교양 과학서 등 장르별 실제 검수 리포트를 공개했다. 리포트에는 AI가 탐지한 오류 항목과 수정 제안, 근거 출처가 카테고리별로 정리돼 있으며, 지난 2월부터 실제 출판물에 적용된 데이터를 기반으로 한다는 점에서 단순 시연 수준을 넘어선다고 업체 측은 전했다.
회사 측은 기존 출판 교정·교열 과정이 전문 인력 여러 명이 수일에서 수주에 걸쳐 수행하는 고비용 구조였으며, 사실관계 오류 역시 개인의 지식 범위에 의존할 수밖에 없었다고 설명했다. 이어 이번 AI 자동 검수 시스템은 맞춤법 교정을 넘어 사실의 진위까지 근거 기반으로 검증하는 새로운 출판 품질 보증 체계를 제시한다고 강조했다.
루미너리북스는 해당 시스템을 이미 자사 출판물에 적용해 효과를 확인했으며, 향후 외부 출판사와 저자, 학술 기관 등을 대상으로 서비스 제공도 검토하고 있다고 밝혔다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>