



글 | 스티브 레이브손(Steve Leibson), 닉 메타(Nick Mehta) 자일링스
자일링스® UltraScale™ 아키텍처는 가장 까다로운 애플리케이션을 위한 ASIC 클래스 시스템 레벨 성능과 함께 전례 없는 통합 수준과 성능을 달성했다. 지난 호에 이어, 이번 호에서는 UltraScale™ 아키텍처의 스마트하고 빠른 프로세싱 실현에 대해 소개한다.
스마트하고 빠른 프로세싱 도전
목표가 패킷 처리량의 증대이든 혹은 더 많은 DSP 및 GMAC, 혹은 스크린 상에 더 많은 초당 메가픽셀 디스플레이이든, 그림 6에 나타낸 것처럼 기술적 과제는 모든 고성능 시스템과 마찬가지이다.
애플리케이션에 상관없이 문제는 매우 간단하다. 대량의 데이터가 포트당 수십에서 수백 기가비트에 이르는 다중 고속 시리얼 포트를 통해 시스템에 들어온다. 이 고속 데이터는 프로세싱 로직으로 라우팅 되어 실시간으로 처리되어야 하며, 이는 고속 데이터 레이트를 처리하는 속도(일반적으로 DSP나 패킷 프로세싱)가 요구되는 작업이다. 들오는 데이터와 중간 결과는 프로세싱 요소에 인접한 시스템 내부나 혹은 시스템에 인접하고 있는 고속 대용량 메모리 중 하나에 저장되어야 한다. 데이터가 처리된 후 다시 나갈 수 있도록 고속 출력 트랜시버로 라우팅되어야 한다. 그림 6은 다음과 같은 내용을 나타내고 있다:
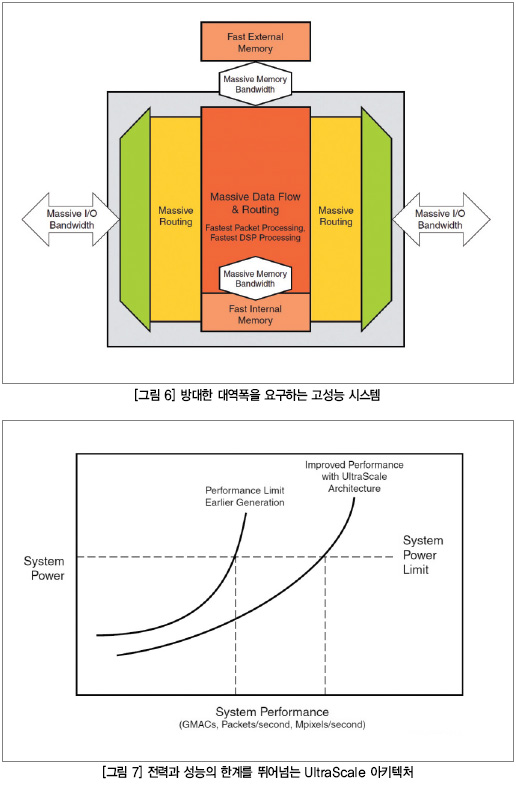
▷ 이러한 고속 시리얼 라인을 통한 시스템 데이터 입력 및 출력은 매우 견고한 멀티-기가비트 시리얼 트랜시버를 통과하는 방대한 I/O 대역폭이 필요하다. 이러한 시리얼 트랜시버는 반드시 안정적이고 낮은 비트 에러율을 가지고 있어야 한다.
▷ 방대한 병렬 라우팅은 멀티-기가비트 시리얼 트랜시버에서 방대한 와이드 기능-프로세싱 블록으로 팬아웃 되며, 낮은 클록 스큐의 와이드 팬아웃 기능이 요구된다. 이러한 병렬 버스를 라우팅 하는 것이 도전과제이다.
▷ 방대한 데이터 플로 프로세싱은 높은 처리량의 로직 및 DSP 블록과 함께 방대한 메모리 대역폭의 메모리 인터페이스를 이용하는 매우 빠른 내부 및 외부 메모리 액세스가 모두 필요하다. 이러한 종류의 프로세싱은 어떠한 아키텍처라도 데이터 및 클록 라우팅 성능에 상당한 압박을 가하게 된다.
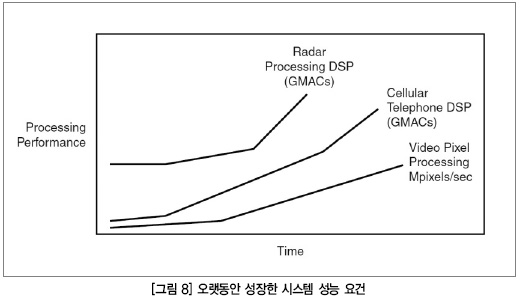
이러한 성능 목표는 모두 정해진 전력소모 한도 내에서 이뤄져야 한다. 시스템은 허용 가능한 전력 및 쿨링 한도 내에서 동작해야 한다. 그림 7에는 이러한 개념의 그래프를 나타내었다.
UltraScale 아키텍처를 구성하는 구성요소들은 여러 차세대 프로세싱 시스템의 매우 복잡한 요건에 맞게 조정되어 있다.
대량 I/O 및 메모리 대역폭
UltraScale 아키텍처는 고속 SerDes 트랜시버와 관련하여 높은 성능 증가와 전력소비 감소를 동시에 달성하고 있다. 버텍스 UltraScale 디바이스는 5 Tbps 초과 직렬 시스템 대역폭을 지원할 수 있는 차세대 SerDes 트랜시버를 제공한다.
UltraScale 아키텍처 기반의 GTY 및 GTH 시리얼 트랜시버는 멀티-Gbps 시리얼 데이터 라인 레이트를 수백 MHz로 동작하고, 온칩 로직 및 메모리 속도와 일치해야 하는 와이드 데이터 버스로 변환시켜주는 내부 기어박스 로직을 갖추고 있다. 이 트랜시버 기어박스는 시스템 디자인 시 외부의 기어박스용 칩 비용을 없애준다. 이와 유사하게 UltraScale 아키텍처 기반의 GTY 시리얼 트랜시버를 위한 통합 PLL(Phase-Locked Loop)은 하나의 레퍼런스 클록을 다중 라인 레이트로 변환시켜 주며, 외부의 VCXO
(Voltage-Controlled Crystal Oscillators)를 사용할 필요가 없다. 이러한 기능은 말 그대로 다른 라인 레이트로 구동하는 여러 고속 시리얼 포트를 이용하는 시스템 디자인에서 여러 개의 디바이스와 수백 달러의 비용을 절감할 수 있도록 해준다.
UltraScale 아키텍처 기반의 ASIC 클래스의 시리얼 트랜시버는 초기 세대 디바이스의 트랜시버에 비해 탁월한 유연성을 갖추고 있으며, 자일링스 7 시리즈 올 프로그래머블 디바이스의 자동-적응형 이퀄라이제이션 기능(자동 게인 컨트롤, 연속적 선형 이퀄라이제이션, DFE(Decision Feedback Equalization))은 유지하고 있다. 자일링스의 자동-적응형 이퀄라이제이션은 감지가 불가능할 정도(예를 들어 <10-17)의 비트 에러율을 제공하며, UltraScale 아키텍처 기반의 트랜시버를 직접 고속, 멀티-GHz 백플레인으로 구동할 수 있도록 해준다.
방대한 외부 및 내부 메모리 대역폭 지원
UltraScale 아키텍처는 다중 DDR3/4 지원 SDRAM 메모리 컨트롤러로 구동되는 새로운 차원의 메모리 인터페이스를 이용하고 있으며, 칩 상에 하드 DDR PHY(Physical-Layer) 블록을 포함하고 있다. 초기 세대 디바이스와 비교해 UltraScale 아키텍처 기반 디바이스는 다음을 포함한다:
▷ 더 많은 SDRAM 컨트롤러
▷ 더욱 확대된 SDRAM 포트
▷ 더욱 빠른 메모리 포트
그 결과 UltraScale 아키텍처 기반의 올 프로그래머블 디바이스는 차세대 첨단 시스템 디자인의 방대한 데이터 플로와 고속 프로세싱, 막대한 메모리 요건을 처리하는 1 Tbps 이상의 DDR SDRAM 메모리 대역폭을 제공할 수 있다. 하드 SDRAM PHY 블록은 소프트-코어 PHY에 비해 읽기 지연을 30%까지 감소시켜주며, DDR4 SDRAM 제어 능력은 외부 메모리에서 필요한 전력을 20% 이상 줄여준다.
온칩 블록 RAM 성능은 시스템의 최대 클록 레이트에 영향을 미치는 중요한 요소가 될 수 있다. 자일링스는 UltraScale 아키텍처 기반 올 프로그래머블 디바이스에서 시스템의 다른 프로그래머블 블록들과 성능은 대등하면서도 전력소모는 감소하도록 블록 RAM을 재설계했다. 이 새로운 블록 RAM 아키텍처는 고속 메모리 캐스캐이딩을 지원하며, DSP 및 패킷 프로세싱의 병목현상을 없애준다. 이 새로운 아키텍처 측면의 기능은 비바도(Vivado) 디자인 수트 툴이 추가적인 온칩 라우팅 및 로직 리소스를 사용하지 않고도, 효율적으로 대규모의 고속 RAM 어레이와 FIFO를 생성할 수 있도록 독창적인 방법으로 출력 멀티플렉서를 이용하고 있다.
또한 자일링스는 동일한 FIFO 상에서 입력 및 출력 포트의 대역폭이 서로 다르도록 UltraScale 아키텍처 기반 블록 RAM FIFO의 컨피규레이션을 개선시켰다. 이러한 기능은 FIFO가 하나의 시스템 클록 도메인에서 다른 도메인에 이르기까지 포괄적으로 사용될 때 도움이 되며, UltraScale 아키텍처는 현재 더 많은 클록 도메인을 지원할 수 있게 되었다.
고속의 스마트 프로세싱 실현
DSP 및 패킷 프로세싱 시스템을 위한 성능요건은 그림 8에 나타낸 것처럼 최종 고객의 요구에 따라 갈수록 증가하고 있다.
노이즈에서 탁월한 신호 정보를 추출하고, 항상 실제와 같은 이미지를 생성하고, 끝없이 증가하는 패킷 트래픽의 처리에 대한 요구는 이러한 성능요건의 증가를 이끌고 있다. 또한 이러한 성능요구는 항상 달성 가능한 실용적인 한계선 안에서 경제적인 방안으로 처리되어야 한다. 그림 9는 LTE 및 LTE-A(LTE-Advanced) 기지국의 시간이 경과하면서 나타나는 성능 대비 비용 흐름을 보여주고 있다.
요컨대 고객들은 더 낮은 비용으로 더 높은 시스템 성능을 원하며, 이는 대부분의 전자산업에서 요구되는 영속적인 경향이기도 하다. 이는 UltraScale 아키텍처를 통해 실현할 수 있다.
향상된 DSP로 성능 개선
자일링스는 이미 업계 선도적인 성능을 갖추고 있는 버텍스-7 FPGA의 DSP48E1 DSP 슬라이스를 DSP 블록 외부의 보다 적은 라우팅 및 로직 리소스만을 사용하면서도 보다 빠른 디지털 시그널 프로세싱을 구현할 수 있도록 대폭 개선했다. DSP 슬라이스에 적용된 수많은 혁신을 통해 곱셈과 MACC 연산을 향상시켰으며 전력소모는 절감시켰다.
UltraScale 아키텍처 기반의 DSP48E2 DSP 슬라이스는 적은 수의 DSP 슬라이스로 더 많은 기능을 매핑할 수 있도록 27×18 bit 멀티플라이어를 통합했다. 예를 들어 더 넓은 대역폭의 27×18 bit 멀티플라이어를 갖춘 DSP48E2 블록은 자일링스 7시리즈 올 프로그래머블 디바이스의 DSP48E1 블록으로 동일한 기능을 구현한 것과 비교해 2~3배 적은 DSP 블록을 이용해 두 배의 정밀도로 IEEE Std 754 연산을 구현할 수 있다.
DSP48E2 슬라이에 포함된 와이드-MUX 및 와이드-XOR 기능은 넓은 대역폭의 고속, 하드 로직 블록의 DSP 슬라이스를 이용해 ECC(Error Correction and Control) 및 CRC(Cyclic Redundancy Checking)와 같은 비-DSP 연산이 가능하도록 해준다. 이러한 개선으로 성능은 증가하고 전력소모는 낮아졌으며, CLB(Configuration Logic Block) 사용률은 줄어들어 다른 기능을 구현하기 위해 더 많은 CLB를 활용할 수 있게 되었다. 이러한 DSP 블록 및 다른 부분들의 혁신을 통해 UltraScale 아키텍처는 차세대 애플리케이션의 증가하는 프로세싱 요건에 부응하는 것은 물론, 동시에 비용절감도 가능하게 되었다.
스마트 패킷 프로세싱을 위한 성능 확장
대역폭에 대한 끝없는 요구는 계속해서 네트워크 통신 인프라를 업그레이드하기 위한 투자를 유발하고 있다. 디지털 비디오 전송으로 인한 방대한 데이터 트래픽은 100 Gbps 기반 네트워킹 장비 시장의 성숙을 가속화시키고 있으며, 400G 솔루션에 대한 요구도 증대시키고 있다. 패킷 프로세싱은 현재 업계에서 제공되는 초당 수백 기가비트에 해당하는 최첨단 아키텍처에서도 상당한 성능적 과제를 야기할 수 있다. 기본적인 패킷 프로세싱 기능은 라인속도로 수행되는 체크섬 연산 및 브리징 기능을 포함하고 있으며, 성능 및 리소스 활용에 상당한 영향을 미칠 수 있다.
고성능 패킷 프로세싱과 관련된 방대한 데이터 플로를 해결하는 것 이상으로 UltraScale 아키텍처는 특별히 패킷 프로세싱을 위해 최적화된 여러 혁신적인 기능을 포함하고 있다. 이 가운데에는 DSP48 블록을 고속으로 CRC 32 체크섬 연산을 지원하도록 수정한 것과 스마트 패킷 프로세싱을 위해 혁신적인 성능과 새로운 차원의 통합을 지원하도록 하드 기가비트 이더넷 MAC과 인터라켄 칩-투-칩 인터페이스가 포함되어 있다.
차세대 시스템의 시스템 레벨 전력 요건 해결
시스템 레벨의 성능이 연이어 다음 세대 제품으로 지속적으로 확장되면서, 전력소모에 대한 기대치(시스템 요건)는 변하지 않거나 계속해서 감소할 것으로 기대되고 있다. 예를 들어, 유선 통신 인프라 장비의 경우, 보다 높은 대역폭과 연산 성능을 지원하는 차세대 라인 카드는 폼팩터나 라인 카드의 전력 면에서 어떠한 변화 없이 이러한 이득을 달성해야 한다.
이는 본질적인 시스템 성능 증가(일반적으로 전력소모 증가를 감수해야 함)와 시스템 레벨의 전력소모 절감 개선이 통합 및 전력관리 전략, 첨단 공정 기술을 통해 지속적으로 달성되어야 한다는 것은 어폐가 있을 수도 있다.
UltraScale 아키텍처는 경쟁 상대 없는 시스템 레벨 전력을 낮추기 위한 올 프로그래머블 로직 제품군의 노력에 기반을 하여 개발된 것이다. 저전력 반도체 공정과 실리콘 및 소프트웨어 기법을 통해 가능했던 상당한 정적 게이팅 및 동적 게이팅은 이미 최저전력 올 프로그래머블 디바이스 자일링스 7 시리즈 FPGA 제품군의 최대 50%까지 전체 시스템 절전을 이루어냈다.
디자이너에게 있어 절전은 열관리 요건을 줄여 전력 예산을 낮추는 것 또는 속도를 높이는 것을 의미한다. 이는 점점 증가하는 차세대 애플리케이션의 요건을 해결하는데 매우 중요한 방편이다.
UltraScale 아키텍처 보안으로 IP 보호, 부정 조작 방지
자일링스 올 프로그래머블 FPGA 사용은 이러한 디바이스가 여러 가지 새로운 시스템의 핵심이 되고 있는 거의 대부분의 마켓 영역으로 계속 확대되고 있다.
자일링스 올 프로그래머블 디바이스가 도처로 확대되면서 디바이스에서 처리되는 데이터 보호는 내부의 IP를 보호하는 것만큼 중요해지고 있다. 보안 위협에 대한 인식이 증가함에 따라 보안 커뮤니티는 디자인 보안 이상으로 요구되고 있는 일련의 정책 및 표준을 통해 이에 대응해 나가고 있다. 디자이너가 안전한 제품을 구축하기 위해 반드시 고려해야 하는 보안 위협 및 잠재적인 취약성 범주는 상당히 광범위하다. 이러한 취약성 부분을 간략히 살펴보면, 자기만족적이고 불완전한 보안 조치 및 부정한 방법, 디자인 결함, 디바이스 결함, 싱글-이벤트 업셋, 비트스트림 디코딩, 위장, 트로이 목마, 재읽기, 사이드 채널, 결함 삽입 등이 있다.
5세대에 걸친 보안 솔루션 및 혁신의 유산을 바탕으로, UltraScale 올 프로그래머블 아키텍처는 디바이스에 장착되는 IP를 추가 보호하고 부정 조작을 방지하는 복수의 강화 보안 기능들을 구현해 자일링스의 리더십을 보안 솔루션까지 확장하고 있다. UltraScale 아키텍처는 AES 비트스트림 해독 및 인증에 대한 보다 강력하고 진화된 접근방식을 제공하고 있다. 대표적으로 키 난독화 기능, 프로그래밍 중 암호화 키에 대한 외부 접속 기능 제거 등이 있다. 그 결과 끊임없이 변화하는 차세대 보안 요건의 지형을 다룰 수 있는 튼튼하고 산업 선도적인 솔루션을 제공할 수 있게 된 것이다.
분석적 상호최적화 = 예측 가능한 성공
가장 까다로운 애플리케이션에 대하여 탁월한 통합 수준과 기능, ASIC급의 시스템 레벨 성능을 제공하는 것은 그리 간단한 일이 아니다. UltraScale 아키텍처는 모놀리식에서 3D IC로의 확장과 더불어, 20 nm 플래나에서 16 nm FinFET 기술을 넘어서 진화하고 있으며, 또한 어떠한 성능 저하 없이 최고 90%의 탁월한 활용도를 제공하고 있다. 이러한 극한의 목표에 부합하기 위한 한 가지 방법은 UltraScale 아키텍처와 비바도 디자인 수트와의 상호최적화 작업으로 달성된다.
자일링스의 7 시리즈 디바이스 제품군에서 처음 도입된 비바도 디자인 수트는 향후 10년 동안의 올 프로그래머블 디바이스를 위한 SoC 강도 디자인 환경으로, UltraScale 아키텍처를 포함하고 있다. 비바도는 프로그래머블 시스템 통합 및 구현 시 발생하는 주요 디자인 병목현상을 공격하여 경쟁 개발 환경보다 최대 4배까지 뛰어난 생산성을 가능하게 해준다.
차세대 디자인에서 뛰어난 성능과 통합, QoR(quality-of-results) 등의 목표를 달성하려면 완전히 새로운 디바이스의 배치 및 라우팅 접근법이 필요하다. 기존 FPGA 플레이스-앤-라우트 툴은 시뮬레이티드 어닐링(simulated annealing)에 의존하고 있으며, 1차 배치 최적화 알고리즘은 정체 수준이나 총 와이어 길이 같은 전체적인 디자인 지표들에 대해서는 파악하지 못한다. 이 알고리즘은 무분별한 배치에서 시작하여 주어진 비용 함수를 최적화한다. 초기 배치의 무분별한 특성과 이후 동작 때문에, 전통적인 시뮬레이티드 어닐링 알고리즘은 여러 이유로 백만 단위의 LUT까지 확장되지 않는다.
첫째로 반복적인 립업(rip-up), 리라우트(reroute) 및 대안 배치의 평가와 관련한 시간이 다루기 어려워진다. 디자인이 보수적인 성능을 가지고 있거나 디바이스 활용에 제한이 있을 때에도 동일하다. 보다 중요한 것은, 시뮬레이티드 어닐링 알고리즘은 로컬 동작에 기반하고 있기 때문에 총 와이어 길이나 정체 수준과 같은 글로벌 디자인 메트릭에 대해서는 무지하다. 멀티 테라비트 성능을 요구하는 디자인에는 사실상 클록 스큐가 “제로(0)”인 와이드 버스가 필요하다. 총 와이어 길이와 정체에 대해 고려하지 않은 시뮬레이티드 어닐링과 같은 플레이스-앤-라우트 알고리즘을 채택하는 것은 적합하지 않다.
최적의 배치 솔루션은 타이밍, 와이어 길이, 정체 메트릭과 같이 여러 가지 요소들로 좌우된다.
비바도 디자인 수트는 다변수 비용함수(multivariable cost function)를 이용해 최적의 배치를 찾아냄으로써 디자이너가 성능 저하 없이 90% 이상의 디바이스 활용도에서도 라우팅 가능한 솔루션을 재빨리 찾아낼 수 있다. 런타임은 다른 솔루션들에 비해 더 빠르면서도 결과 편차는 매우 적기 때문에 업계에서 유례없는 성능 수준과 디바이스 활용도로 보다 적은 반복적인 작업으로 디자인 완료가 가능하다.
UltraScale 아키텍처와 프로세스 기술
프로세스 기술은 칩 아키텍처에서 매우 중요한 고려사항이다. 자일링스의 UltraScale 아키텍처는 복수의 프로세스 기술을 하나로 포괄하도록 설계돼 있다. 자일링스와 TSMC는 자일링스의 7 시리즈 올 프로그래머블 디바이스에 엄청난 성공을 가져다 준 핵심 요소인 28나노 HPL(저전력 고성능) 프로세스 기술을 협력 개발했다. 이러한 경험을 살려 자일링스와 TSMC는 20나노 20SoC 플래너 프로세스를 개발하였고, 자일링스의 1세대 UltraScale 올 프로그래머블 디바이스를 완성하게 되었다. 이 디바이스는 올해 첫 번째 실리콘을 출시할 예정이다.
자일링스가 UltraScale 아키텍처를 디자인한 이유는 이뿐만이 아니다. 바로 20SoC의 뒤를 잇는 프로세스 노드, 이른바 16 nm FinFET에 추가적인 성능, 역량, 절전을 활용하기 위함이다. 자일링스 UltraScale 아키텍처와 비바도 디자인 수트는 독특한 자일링스의 “핀패스트(FinFAST)” 개발 프로그램을 통해 TSMC 16nm FinFET 프로세스 기술과 상호 최적화 되었다. 그 결과 자일링스와 TSMC는 2세대 UltraScale 올 프로그래머블 디바이스의 첫 번째 실리콘을 2014년에 생산할 예정이다.
결론
전체 라인 레이트에서 스마트 프로세싱으로 초당 수 백 기가비트 레벨의 시스템 성능을 처리하고 테라비트와 테라플롭으로 확장하려면 새로운 아키텍처 방식이 필요하다. 자일링스는 차세대 고성능 시스템의 요건을 염두에 두고 차세대 UltraScale 아키텍처와 비바도 디자인 수트를 개발하였다. UltraScale 아키텍처는 대부분의 까다로운 차세대 애플리케이션에서, 즉 성능 저하 없이 90% 이상의 유례없는 활용률로 대량 I/O및 메모리 대역폭, 대량 데이터 흐름, 대량 DSP, 패킷 프로세싱 성능 등을 요구하는 차세대 애플리케이션에서 ASIC 클래스의 시스템 레벨 성능을 발휘한다.
UltraScale 아키텍처는 20나노 플래너로부터 16나노를 거쳐 핀펫(FinFET) 기술 너머까지, 모놀리식부터 3D IC까지 이르는 단계까지 확장될 수 있도록 올 프로그래머블 아키텍처에 최신 ASIC 아키텍처 개선사항을 업계 최초로 적용했다. TSMC의 최신 기술과 비바도짋 디자인 수트와의 최적화를 통해, 자일링스는 경쟁사보다 1년 이상 앞선 기술력으로 1.5~2배 이상 신뢰성 있는 시스템 레벨 성능과 통합을 제공한다. 이는 자일링스가 경쟁사보다 한 세대 앞선 기업임을 증명하는 것이다. ES
| 올 프로그래머블 앱스트랙션 확대 자일링스는 하드웨어 디자이너의 생산성을 향상하고 시스템 및 소프트웨어 개발자가 올 프로그래머블 FPGA, SoC 및 3D IC를 직접 이용할 수 있도록 올 프로그래머블 앱스트랙션 이니셔티브(Abstractions Initiative)를 발표했다. 자일링스와 매스웍스(MathWorks) 및 내쇼날인스트루먼트(National Instruments, 이하 NI) 등이 포함된 에코시스템 얼라이언스 회원사들은 소프트웨어, 모델, 플랫폼, IP 기반 디자인 환경의 결합을 지원한다. 이러한 환경을 통해 C, C++, SystemC와 같은 고차원적 그래픽과 텍스트 기반 프로그래밍 언어를 구현하고, 최적화된 실행으로 변환할 수 있는 OpenCLTM(Open Computing Language)까지 지원할 예정이다. 소프트웨어 및 시스템 앱스트랙션은 하드웨어 중심 IP 통합과 C 기반 디자인 앱스트랙션을 보완한다. 또한 복잡한 FPGA와 SoC의 개발을 기존 RTL 플로우와 비교해 최대 15배까지 가속화할 수 있다. 지능형 오류 제거 기술 어셈블리 제공 자 일링스는 올 프로그래머블 디바이스의 고집적과 복잡한 디자인을 가속화하기 위해 비바도(Vivado)짋 IPI(IP Integrator)를 제공한 바 있다. 비바도 IPI는 IP 패키징을 위한 ARM짋 AXI 인터커넥트 및 IP-XACT 메타데이터와 같은 산업 표준에 기반을 둬 자일링스 올 프로그래머블 솔루션에 최적화된 지능형 오류 제거 기술 어셈블리(Intelligent correct-by-assembly)를 제공한다. 따라서 Zynq-7000 올 프로그래머블 SoC를 대상으로 하는 임베디드 디자인 팀들은 듀얼코어 ARM 프로세싱 시스템 및 고성능 FPGA 패브릭을 위한 소프트웨어 및 하드웨어 IP를 신속하게 식별, 재사용 및 통합할 수 있다. 자일링스 올 프로그래머블 앱스트랙션은 Zynq-7000 올 프로그래머블 SoC와 마이크로블레이즈(MicroBlaze) 프로세서의 소프트웨어 개발 시간을 단축한다. 자일링스는 시스템 하드웨어/소프트웨어 인터페이스를 에뮬레이션하는 QEMU(Quick Emulator) 오픈 소스 가상화 머신을 개발했다. 이전 소프트웨어 개발로 더 높은 생산성과 지속적인 하드웨어/소프트웨어 통합 검증이 가능했다. 또한 케이던스 디자인 시스템즈(Cadence Design Systems)와 협력을 통해 자일링스의 Zynq-7000 올 프로그래머블 SoC를 대상으로 가상 시스템 플랫폼을 제공해 하드/소프트웨어를 동시 개발이 가능하다. 따라서 개발 비용과 시간을 단축할 수 있다. 이들 가상 환경은 자일링스의 SDK(software Development Kit)와 함께 이용하면, 시스템 개발 일정을 수개월 단축할 수 있다. |
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



