



자료 제공|알테라
이 글에서는 알테라의 40nm 및 28nm FPGA를 이용해서 통합 HD 스튜디오 장비 제품군을 구현하기에 어떤 점이 적합한지 설명한다. 또한 다중 비디오 채널의 포맷 변환에 필요한 성능 요구 사항, 리소스 사용, 소비 전력 특성에 대해서 알아본다. 이 기능은 비디오 캡쳐 카드, 멀티 뷰어, 비디오 월, A/V 스위치에 이르는 다양한 방송용 애플리케이션에 공통적으로 사용되는 기능이다. 특히 방송용 애플리케이션의 성능을 향상시킬 수 있도록 하기 위한 알테라 28nm FPGA의 내부 아키텍처의 성능 향상에 대해서 설명한다.
개요
HD 비디오 채널 수에 대한 업계의 수요가 높아짐에 따라서 스튜디오 장비 업체들은 대역폭과 프로세싱 성능을 만족하면서 가격과 전력은 최소화하는 제품을 내놓아야 하는 과제에 직면해 있다.
비록 일부 스튜디오 장비 업체들은 full custom ASIC을 채택했지만, 긴 개발 기간과 높은 개발 비용 때문에 많은 경우에는 이 방법을 택하는 것이 불가능하다. 일부 애플리케이션에는 ASSP(application-specific standard products)가 대안이 될 수 있겠지만, ASSP는 시장의 요구에 빠르게 대응할 수 없고 높은 집적화가 어렵다.
알테라는 이러한 문제를 해결할 수 있도록 스튜디오 장비 개발자들이 ASSP 기반 시스템보다 더 높은 수준의 집적화 및 맞춤화를 가능하게 하면서, full custom ASIC의 긴 개발 시간과 높은 비용을 피할 수 있도록 최신의 40nm 및 28nm FPGA 제품들을 제공한다.
UDX
Up/Down Cross Conversion
저장, 인코딩, 디스플레이하기 전에 비디오를 변환하는 작업은 상향/하향 교차 변환 (Up/Down Cross Conversion: UDX) 으로 설명할 수 있다.
(그림 1)은 알테라가 개발한 2채널 UDX 디자인의 개략적인 블록 다이어그램이다. 이 디자인은 단순한 포맷 변환 이외에도 다수의 포괄적인 여러 기능들을 포함하므로 대부분의 애플리케이션은 이보다 더 적은 리소스를 사용할 것이다. 이 디자인을 이용해서 스튜디오 장비 제품을 구현할 때 알테라 FPGA의 적합성, 성능, 전력 특성에 대해 살펴보도록 하겠다.
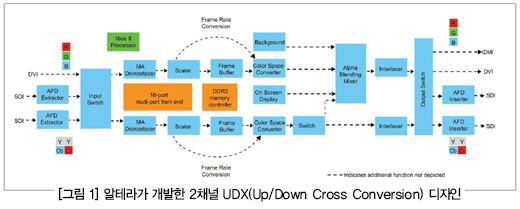
이 2채널 UDX 디자인은 SDI(serial digital interface)나 DVI(digital visual interface)를 통해서 비디오를 입력 받는다. 이 디자인은 입력 해상도가 NTSC, PAL, 720p, 1080i, 1080p이고 최대 1080p60인 2개의 SD-SDI, HD-SDI, 3G-SDI 순차 또는 비월 주사 입력을 처리할 수 있다.
AFD(Active Format Description) 추출기는 SDI 채널로부터 코드를 추출해서 4:3 및 16:9 종횡비 사이의 양방향 형식 변환을 하고, 이때 다이내믹 클리핑, 스케일링, 패딩이 가능해야 한다. 그런 다음 입력 스위치는 3개 입력 스트림 중에서 2개를 선택하는데, 필요에 따라서 4:2:2 대 4:4:4 크로마 샘플링 변환을 한다.
비디오 프로세싱 채널에서는 모션 적응식(motion-adaptive) 디인터레이서가 비디오 입력을 4:2:2 모드로 디인터레이싱하고 각 입력 필드에 한 출력 프레임씩 외부 RAM으로 더블 버퍼링한다.
그런 다음 이 비디오 프레임을 원하는 해상도로 스케일링하고 프레임 레이트 변환을 위해서 외부 메모리에 버퍼링한다. 이렇게 변환된 영상을 두 번째 채널 및 로고와 믹싱하고 SDI, DVI, HDMI 같이 사용자가 선택한 출력으로 영상을 표시한다.
이 UDX 디자인을 하드웨어로 성공적으로 구현하고 시연하였다.
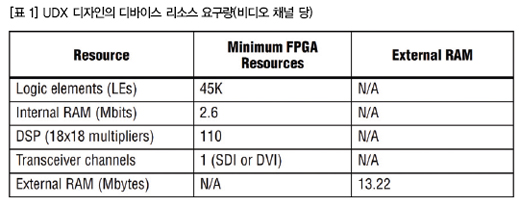
리소스 및 메모리 요구량 계산
알테라 UDX 디자인의 메모리 대역폭은 디인터레이싱과 관련된 프레임 버퍼링에 의해서 결정된다. (표 1)은 이 UDX 디자인의 채널당 디바이스 리소스 요구량을 보여준다.
1080p 메모리 대역폭
메모리 대역폭은 한 채널이 처리해야 하는 최대 해상도 비디오에 따라서 결정된다. 이 디자인은 최대 1080p의 비디오를 처리하므로 다음과 같은 공식을 이용해서 1080p 비디오를 버퍼링 하기 위해 필요한 메모리 대역폭을 계산할 수 있다:
= 1920 × 1080 = 2073600 bits
2073600 × 60 FPS × 2 color planes × 10 bit resolution = 2.48832 Gbps
1080p 비디오를 쓰기 위해서 필요한 최소한의 메모리 대역폭은 2.48832Gbps이다. 하지만 이 디자인은 메모리 인터페이스의 width에 따른 최대 워드 크기를 고려해야 한다.
FPGA의 메모리 인터페이스가 64비트 메모리 인터페이스로 가정했을 때 최대 워드 크기는 256비트 워드이다. 그러나 픽셀이 분할되지 않도록 사용하기 위해서 12개의 20비트 픽셀을 쓰고 16비트는 사용하지 않는다. 즉 256비트 중에서 240비트를 사용한다.
12 pixels×20 bits = 240 bits
그러므로 64비트 메모리 인터페이스로 픽셀을 분할하지 않고 1080p 비디오를 읽거나 쓰기 위해서 필요한 실제 대역폭은 다음과 같이 나타낼 수 있다:
2.48832 Gbps × (256/240) = 2.654208 Gbps
모션 적응식 디인터레이싱 알고리즘
모션 적응식 디인터레이싱 알고리즘(motion-adaptive deinterlacing algorithm)은 1080i로 한번 쓴 후 1080i로 4회 읽거나 1080p로 2회 읽는 과정이 필요하다:
1 write @ 1080i = 0.5×2.654208 Gbps = 1.327104 Gbps
4 reads @ 1080i or 2 reads @ 1080P = 2×2.654208 Gbps
= 5.30816 Gbps
Total = 6.635264 Gbps
만약 디인터레이서에 모션 블리드(motion bleed) 기능이 포함되면 현재 프레임의 모션을 저장하고 이전에 저장된 값과 비교해야 한다. 모션 적응식 디인터레이싱 알고리즘 역시 비디오 모션 값을 1회 읽기 및 1회 쓰기를 해야 한다. 그러므로 10비트 모션 값이라고 가정했을 때 매 읽기 또는 쓰기에 필요한 최소 대역폭은 다음과 같다:
1920×1080×60/2 FPS×10 bits = 0.622 Gbps
모션 값 하나가 10비트라고 했을 때 단일 256비트 워드에 총 25개 모션 값을 집어넣을 수 있다. 256비트 워드로 픽셀이 분할되는 것을 피하기 위해서는 필요한 대역폭은 다음과 같다:
0.622 Gbps×(256/250) = 0.637 Gbps
그러므로 단일 채널의 모션 적응식
디인터레이싱에 필요한 메모리 대역폭은 다음과 같다:
6.635264 Gbps + (2×0.637 Gbps) = 7.90953984 Gbps
마찬가지로 프레임 버퍼에 필요한
대역폭은 하나의 1080p 프레임을 읽고 쓰기 위해서 필요한 메모리 요구량을 더해서 계산할 수 있다:
2.48832 Gbps×(256/240)*2 = 5.308 Gbps
그러므로 하나의 UDX 채널에 필요한 총 메모리 대역폭은 디인터레이서와 프레임 버퍼의 메모리 대역폭 요구량을 더한 것이다:
7.90953984 Gbps + 5.308Gbps = 13.21795584 Gbps, or ~13.22 Gbps
40nm 및 28nm FPGA를 이용한 UDX 디자인 구현
(그림 2)는 간단한 2채널 UDX 디자인으로 캡쳐 카드의 일반적인 형태이다.
이 2채널 UDX 디자인의 메모리 대역폭은 다음과 같이 계산할 수 있다:
2 channels ×13.22 Gbps = 26.44 Gbps
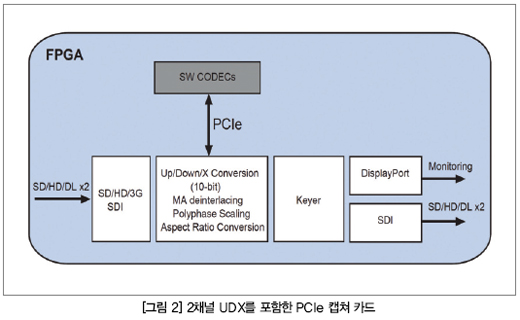
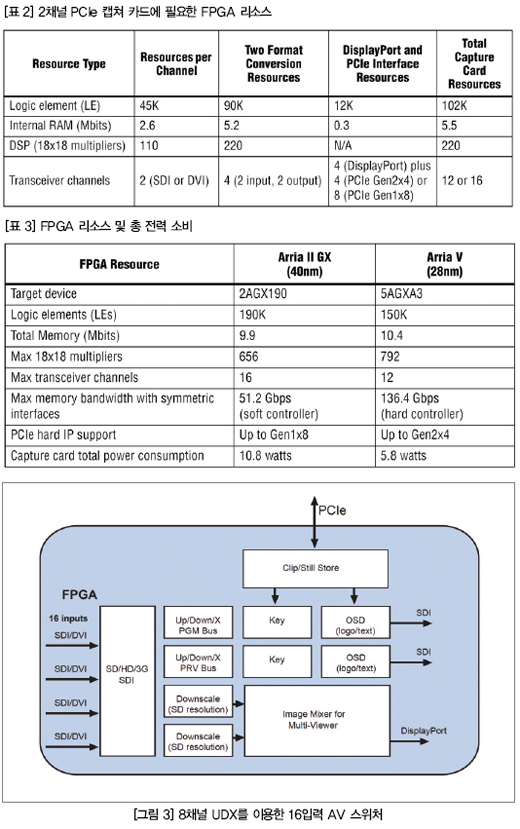
(표 2)는 모니터링을 위한Display Port 출력과 호스트로 비디오 데이터를 전송하고 소프트웨어 코덱을 액세스하기 위한 PCIe 인터페이스를 포함한 2채널 PCIe 캡쳐 카드에 필요한 리소스를 보여준다.
(표 3)은 캡쳐 카드 디자인에 가장 적합한 40nm 및 28nm FPGA와 관련된 디바이스 리소스의 수를 보여준다.
최대 메모리 대역폭은 대칭 인터페이스(다시 말해서 최소한 2개 인터페이스가 동일한 width 및 속도)를 이용했을 때의 것을 표기하였다. 때로는 각기 다른 데이터 width나 속도의 추가적인 인터페이스를 이용함으로써 FPGA가 더 높은 메모리 대역폭을 지원할 수 있다.
하지만 이렇게 하는 것은 바람직하지 않으므로 대칭 인터페이스를 이용할 때의 최대 대역폭만 표시하고 있다. (표 3) 에서 보듯이 두 FPGA 모두 26.44Gbps의 메모리 대역폭 요구를 수월하게 충족한다.
그리고 (표 3)에서는 해당 디바이스의 메모리 인터페이스 지원 특성에 대해서 알 수 있다. 알테라의 40nm FPGA는 사용자 프로그래머블 로직과 메모리 부분에 구현할 수 있는 소프트 메모리 컨트롤러를 통해서 외부 메모리 인터페이스를 할 수 있다. 이와 같은 소프트 메모리 컨트롤러를 이용해서 UDX 디자인을 실제 하드웨어로 시연하고 테스트를 하였으며 효율과 대역폭이 검증되었다.
28nm Arria V FPGA는 메모리 인터페이스를 하드 메모리 컨트롤러로 구현한다. 이 하드 메모리 컨트롤러는 검증된 소프트 메모리 컨트롤러를 기반으로 하며, 더욱 높은 효율을 달성할 수 있도록 설계되었을 뿐만 아니라 편리하게 타이밍을 맞출 수는 빌트인 환경을 제공한다.
(표 3)의 마지막 항목은 이 캡쳐 카드 디자인을 각 디바이스로 구현했을 때의 총 전력 소비를 보여준다. 이 전력은 PowerPlay Early Power Estimator (EPE) 툴을 이용해서 계산한 것이다. 두 FPGA 디바이스 모두 총 전력 소비가 가장 낮은 것으로서, 갈수록 더 전력에 민감해지는 방송용 분야에서 매우 큰 장점이 될 수 있다.
이 UDX 디자인을 기반으로 한 대형 디자인은 FPGA의 높은 집적화를 이용해서 활용할 수 있다. 그러한 예로서 (그림 3)에서 보는 것과 같은 16입력 8채널 A/V 스위처를 들 수 있다.
(그림 3)의 이 디자인은 오직 하나의 FPGA만을 이용해서 구현할 수 있다. 이 디자인을 ASSP로 구현하려면 여러 개의 ASSP가 필요할 것이며 거기에 따라서 보드 크기가 커지고 전력 소비가 늘어나며 디자인이 복잡해질 것이다.
하나의 FPGA로 이 디자인을 구현하기 위해 첫 번째 해야 할 작업은 다음과 같이 8채널 UDX에 필요한 메모리 대역폭을 계산하는 것이다:
8 channels ×13.22 Gbps = 105.76 Gbps
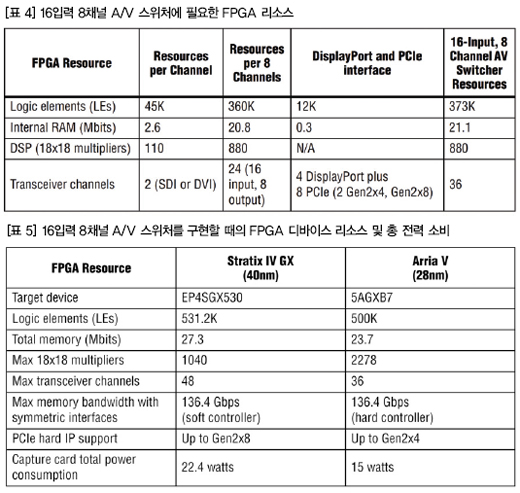
(표 4)에서는 모니터링을 위한 DisplayPort 출력과 호스트로 비디오 데이터를 전송하고 클립 및 스틸 이미지를 획득하기 위한 PCIe 인터페이스를 포함한 16입력 8채널 스위처에 필요한 리소스를 요약해서 보여주고 있다.
(표 5)는 이 16입력 8채널 A/V 스위처 디자인에 적합한 40nm 및 28nm FPGA와 이들 각각의 디바이스 리소스 수를 보여주고 있다. 이 표에서 볼 수 있듯이 대칭 인터페이스만 이용해서 최대 메모리 대역폭을 계산하고 있으며, 두 디바이스 모두 105.76Gbps의 메모리 대역폭 요구를 수월하게 충족하는 것을 알 수 있다.
이들 FPGA 디바이스는 단일 칩으로 이와 같은 복잡한 디자인을 구현할 수 있을 뿐만 아니라 가장 낮은 총 전력 소비를 달성할 수 있으므로 가장 매력적인 솔루션이라 할 수 있다. 뿐만 아니라 이 UDX 디자인과 관련 메모리 컨트롤러 아키텍처의 기반 기술이 모든 FPGA에 일관적이므로 설계 엔지니어는 차세대 FPGA로 이전하기가 용이하다는 이점이 있다.
방송용 애플리케이션에 적합하도록 최적화
알테라는 알고리즘과 실제 구현의 일관성을 유지할 수 있도록 뿐만 아니라 방송용 애플리케이션의 요구를 더 잘 충족할 수 있도록 28nm FPGA의 특정한 아키텍처를 향상시켰다.
최적화된 비디오 임베디드 메모리 블록
알테라는 10비트 비디오 데이터를 효율적이고 정확하게 사용할 수 있도록 임베디드 메모리 블록을 구성하였다. 이렇게 함으로써 알테라 28nm 디바이스로 제공하는 임베디드 메모리 블록의 비트를 낭비하지 않으면서 width를 10씩 증가해서 (다시 말해서 x10, x20, x40으로) 구성할 수 있다.
이전의 FPGA 아키텍처는 임베디드 메모리 블록을 18비트 및 36비트 width로 만들어져서 방송용 분야에서 사용하는 width와 달라 최적화가 어려웠다. 이러한 비트 폭은 비효율을 야기하고, 메모리를 낭비하고, 필요한 메모리 자원을 확보하기 위해서 더 큰 디바이스를 이용해야 한다.
가변 precision DSP 블록
또 다른 방송용 분야에 적합한 최적화는 가변 precision DSP 블록을 도입했다는 것이다. 이들 블록은 9x9, 18x18, 27x27를 비롯해서 다양한 precision의 곱셈기를 구현할 수 있다. 또한 가변 precision DSP 블록을 연속적으로 연결해서 더 높은 precision의 곱셈기를 효율적으로 구현할 수 있다.
예를 들어서 이 UDX 디자인은 최대 10x16(10비트 x 최대 16비트 계수)에 이르는 곱셈을 필요로 한다. 각각의 가변 precision DSP 블록은 2개의 18x18 precision 곱셈기를 구현할 수 있으므로 이 UDX 디자인이 필요로 하는 10x16 최대 precision을 구현을 충족할 수 있다.
예전의 FPGA 아키텍처는 10x16 곱셈을 위해서 DSP 블록 전부를 필요로 할 수 있으며, 이전의 DSP 블록은 하위 precision으로 분해할 수 없으므로 필요한 것보다 더 많은 FPGA 리소스를 사용해야 하므로 구현이 비효율적일 수밖에 없었다.
트랜시버 전력 감소
또 다른 중요한 최적화는 트랜시버 전력을 낮춘 것이다. 많은 방송용 애플리케이션이 갈수록 더 많은 SDI 채널을 필요로 하므로 더 많은 트랜시버 채널을 필요로 한다.
만약에 최종 디자인이 많은 양의 전력을 소비해서 추가로 냉각을 하기 위한 비용이 필요하게 되어 제품의 경쟁력을 떨어트린다면 아무리 고도의 집적화 수준을 자랑한다 하더라도 그 이점이 반감될 것이다.
알테라는 트랜시버 전력을 낮추어온 그동안의 경험을 바탕으로 28nm에서도 트랜시버의 채널당 전력을 낮추었다. 그럼으로써 디자이너들이 단일 디바이스로 더 많은 트랜시버 채널을 통합할 수 있으며 또한 방열 비용을 그대로 유지하거나 낮출 수 있다.
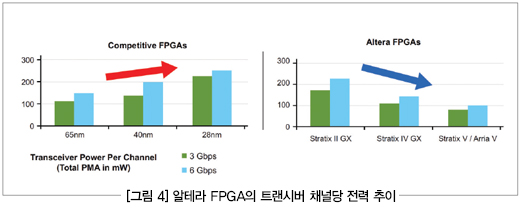
(그림 4)는 3개 세대의 FPGA 제품에 걸친 트랜시버 전력의 추이를 보여주는 것으로서 이 그림을 보면 알테라가 트랜시버 전력을 낮추기 위해서 얼마나 애써 왔으며 또한 얼마나 잘 낮추어 왔는지를 알 수 있다.
이러한 성과는 업계에서 10여년 넘게 독보적으로 쌓아온 트랜시버 기술력 덕택에 가능했던 것이다. 트랜시버 전력을 크게 낮춤으로써 알테라는 총 전력이 가장 낮은 FPGA를 제공할 수 있게 된 것이다.
결론
최신의 FPGA를 이용함으로써 오늘날 방송용 장비 개발자들이 직면하고 있는 대역폭 및 전력 상의 과제들을 해결할 수 있다.
FPGA를 채택하는 장비 개발자들은 고도로 집적화된 하드웨어 가속화 비디오 프로세싱과 업체에서 제공하는 IP 프레임워크를 유용하게 활용할 수 있을 것이다. 이러한 프레임워크는 공통적으로 사용하는 비디오 블록을 제공하므로 개발자들은 고유의 차별화된 기능에 집중해서 개발할 수 있다.
알테라는 저전력 기법과 검증된 비디오 프로세싱 기법을 결합한 FPGA 디바이스 제품을 제공하므로써 위험성을 최소화할 뿐만 아니라, 방송용 분야 애플리케이션에 적합하도록 아키텍처를 향상시켰고 저전력을 위한 최적화를 이루었다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



