



Javier Orensanz|ARM 디버그 툴 담당 매니저
모바일 인터넷 기기 시장의 경쟁이 점점 더 치열해짐에 따라, 신제품의 성공 여부는 뛰어난 성능, 반응이 빠른 소프트웨어 및 긴 배터리 수명에 의해 좌우되고 있다. PC 중심의 시대에는 하드웨어의 클록 주파수를 높임으로써 성능을 향상시킬 수 있었지만, 사용자들이 언제나 인터넷에 연결되기를 원하는 오늘날에는 더 이상 이러한 방법이 통용되지 않는다. 긴 배터리 수명을 유지하면서도 높은 성능을 구현하는 유일한 방법은 바로 기기를 보다 효율적으로 만드는 것이다. 성능과 전력 최적화는 새로운 리눅스 및 안드로이드 제품을 위한 가장 중요한 고려사항이다. 본 글에서는 가장 널리 사용되고 있는 성능 및 전력 프로파일링 방법들과, 제품 설계에서 각각의 단계에 대한 이들 애플리케이션에 대해 알아본다.
효율성 향상 과제의 대두
스마트폰, 태블릿 PC 등 모바일 인터넷 기기 시장의 경쟁이 점점 더 치열해짐에 따라, 신제품의 성공 여부는 뛰어난 성능, 반응이 빠른 소프트웨어와 긴 배터리 수명에 의해 좌우되고 있다.
PC 중심의 시대에는 하드웨어의 클록 주파수를 높임으로써 성능을 향상시킬 수 있었지만, 사용자들이 언제나 인터넷에 연결되기를 원하는 오늘날에는 더 이상 이러한 방법이 통용되지 않는다. 긴 배터리 수명을 유지하면서도 높은 성능을 구현하는 유일한 방법은 바로 기기를 보다 효율적으로 만드는 것이다.
효율성에 대한 요구는 하드웨어적 측면에서 낮은 실리콘 지오메트리와 SoC(시스템-온-칩) 통합을 가져왔고, 소프트웨어 측면에서는 성능 분석이 설계 플로우의 일부분으로 통합될 필요가 있다.
프로세서 명령어 트레이스(Processor Instruction Trace)
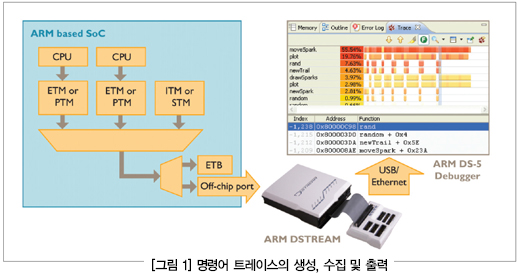
리눅스에서 작동하는 대부분의 ARM 프로세서 기반 칩셋들은 CoreSight ETM(Embedded Trace Macrocell) 혹은 PTM(Program Trace Macrocell)을 포함하고 있다.
ETM과 PTM은, on-chip ETB(Embedded Trace Buffer), 또는 외부 트레이스 장비에 저장될, 프로세서가 실행하는 모든 명령어의 압축된 트레이스를 생성한다. 소프트웨어 디버거는 명령어 리스트를 재구성하거나 프로파일링 리포트를 작성하기 위해 이러한 트레이스를 불러올 수 있다.
예를 들어 DS-5TM 디버거는 ARM DSTREAM 타겟 연결 유닛을 통해 4GB의 명령어 트레이스 수집이 가능하며, 시간 기반 함수 히트 맵을 보여줄 수 있다.
명령어 트레이스는 성능 분석을 위해 매우 유용하게 사용될 수 있는데, 이는 100% 비개입적이면서도 가능한 최상의 입도(granularity)에서 정보를 제공하기 때문이다. 예를 들어, 명령어 트레이스를 사용하면 두 명령어 사이에 발생하는 지연시간을 정확히 측정할 수 있는데, 불행하게도 트레이스는 몇 가지 실행 상의 한계를 지니고 있다.
첫 번째 한계는 상업적인 측면이다.
하나의 단일 SoC에 집적되는 프로세서의 수가 늘어나고, 점점 더 높은 주파수에서 동작하게 됨에 따라, CoreSight 트레이스 시스템에서 요구되는 대역폭은 더 높아졌고, 더 넓고 더 고비용의 오프칩 트레이스 포트를 필요로 하게 되었다.
시스템이 최고 속도로 동작하기 위해 지속 가능한 유일한 해결책은, 1ms 이하 속도로 캡처를 제한하는 내부 버퍼로 트레이스하는 것이다. 이는 전화 통화처럼 전체적인 소프트웨어 태스크를 위한 프로파일링 데이터를 생성하는 데는 충분하지 않다.
두 번째 한계는 실행상에 있다.
리눅스와 안드로이드는 복잡한 다층 구조 시스템(Multi-layered systems)으로, 명령어 트레이스 스트림 내의 유의미한 이벤트를 찾아내는 것이 어렵다. 트레이스 검색 유틸리티(Trace search utilities)가 이를 돕고 있지만, 4GB의 압축된 데이터 속에서 이를 찾아내는 데는 매우 많은 시간이 소요된다.
세 번째 한계는 기술적인 측면이다.
디버거는 트레이스 스트림을 압축 해제하기 위해, 어떠한 애플리케이션이 타겟에서 실행되고 있고 어떤 주소에 로드 되었는지를 알고 있어야 한다. 오늘날의 기기들은 트레이스 스트림을 커널 컨텍스트 스위치 정보와 동기화 하도록 하는 기반 구조를 갖추고 있지 않은데, 이는 콘텍스트 스위치를 통해 전체 트레이스 스트림의 캡처 및 비개입적 압축해제가 불가능하다는 뜻이다.
샘플링 기반 프로파일링
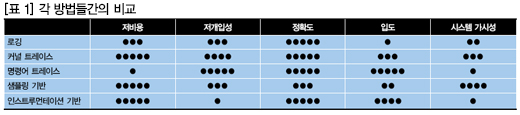
장기간에 걸친 성능 분석을 위한 샘플링 기반 분석 기법은 낮은 개입성과 가격, 정확성이라는 매우 좋은 절충안을 제공한다. 리눅스 샘플링 기반 프로파일링 툴 중 대중적인 것은 Oprofile이다.
샘플링 기반 툴은 프로파일링 리포트를 생성하기 위해, 타이머 인터럽트를 사용해 프로세서를 일정한 주기로 정지시키고 프로그램 카운터의 현재 값을 캡처한다. 예를 들어 Oprofile은 각각의 프로세스, 스레드, 함수 또는 소스코드의 라인마다 프로세서가 소요한 시간을 나타내기 위해 이러한 정보들을 이용한다. 이는 개발자들에게 코드의 중요한 지점(hot areas of code)을 쉽게 파악할 수 있도록 해준다.
약간 더 높은 개입 수준에서, 샘플링 기반 프로파일러는 또한 콜 패스(call-path) 리포트를 생성하기 위해 모든 샘플에서 콜 스택을 역추적할 수 있다. 이렇게 생성된 리포트는 프로세서가 각각의 콜 패스에 시간을 얼마나 사용했는지를 보여주고, 수동 함수 인라이닝과 같은 차별된 최적화를 가능하게 한다.
샘플링 기반 프로파일러는 JTAG 디버그 장비나 트레이스 장비를 필요로 하지 않으므로, 트레이스 기반 프로파일러에 비해 훨씬 비용이 적게 든다. 단점이라면, 샘플링 기반 프로파일러는 모든 샘플마다 얼마만큼의 정보를 캡처하느냐에 따라 타겟을 5~10% 가량 느리게 한다.
샘플링 기반 프로파일러는 “완벽한 데이터”가 아니라 “통계적으로 유의미한 데이터”를 제공한다는 점을 상기하는 것이 중요한데, 이는 프로파일러가 모든 단일 명령어 대신 샘플에 대해 작동하기 때문이다. 이러한 점 때문에, 주요 함수(Hot function)에 대한 프로파일링 데이터는 매우 정확하지만 그 외의 코드에 대한 프로파일링 데이터는 정확하지 않다. 개발자들은 대부분 중요한 코드(Hot code)에만 관심을 기울이기 때문에 대체로 이러한 점이 크게 문제시 되지는 않는다.
샘플링 기반 프로파일러의 마지막 한계점은, 짧고도 중요한 연속적 코드의 분석과 관련이 있다. 프로파일러는 해당 코드에 얼마나 많은 시간이 소요됐는지 알려주지만, 오직 명령어 트레이스만이 어떤 명령어가 실행되었고 얼마의 시간이 소요되었는지의 연속적 코드의 세부적인 사항을 제공할 수 있다.
로깅과 커널 트레이스
로깅이나 어노테이션은 시스템 성능을 분석하는 전통적인 방법이다. 가장 단순한 형태로서, 로깅은 코드의 다른 장소들에서 각각의 타임스탬프와 함께 프린트 스테이트먼트를 추가하는데 있어 개발자에게 의존한다. 도출된 로그 파일은 각 조각의 코드가 실행되기 위해 얼마나 오래 걸렸는지를 보여준다.
이 방법은 간단하면서 저렴하다. 그러나 이 방법의 주요 문제점은, 코드의 각기 다른 부분을 측정하기 위해서는 코드를 계측하고 또 리빌드 해야 한다는 것에 있다. 애플리케이션의 사이즈에 따라 이 작업은 대단히 많은 시간이 소요될 수 있는데, 일례로, 많은 회사들이 밤새도록 오직 소프트웨어 스택을 리빌드 하기도 한다.
리눅스 커널은 트레이싱(Tracing)이라고 부르는, 보다 진화된 형태의 로깅을 위한 기반 구조를 제공한다. 트레이싱은 예전에는 IRQs, 시스템 콜(System calls), 스케줄링(Scheduling) 및 이벤트 애플리케이션용 이벤트(Event application-specific events)와 같은 다수의 시스템 레벨 이벤트를 자동적으로 기록하기도 했다.
최근에는 프로세서에 의해 실행되는 캐시 사용, 혹은 명령어의 수와 같은 하드웨어와 연관된 정보들을 담고 있는 프로세서의 성능 카운터에 대한 엑세스를 함께 제공하도록 커널이 확장되고 있다.
커널 트레이스를 사용해 성능을 분석하는 데는 두 가지 방법이 있다. 첫째, 어떤 이벤트가 예상보다 더 빈번하게 발생하는지의 여부를 체크하기 위해 사용할 수 있다. 예를 들어, 애플리케이션이 동일한 시스템 콜을 단 한 번 요구되었는데도 불구하고 수차례 생성되는 것을 검출해 내는데 사용된다. 둘째, 두 이벤트간의 지연시간(latency)을 측정하고 이를 개발자의 기대값 혹은 이전 운영 시와 비교하는 데 사용될 수 있다.
커널 트레이스가 상당히 비개입적인 방식으로 실행되기 때문에, 리눅스 커뮤니티에서는 perf, ftrace 및 LTTng와 같은 툴이 널리 사용되고 있다. 새로운 리눅스 개발은 개입성을 보다 줄이고 이벤트와 명령어 트레이스간의 더 나은 동기화를 제공하기 위해, 이벤트가 CoreSight ITM(Instrumentation Trace Macrocell)이나 STM(System Trace Macrocell)에 “프린트”될 수 있도록 할 것이다.
샘플링과 커널 트레이스의 결합
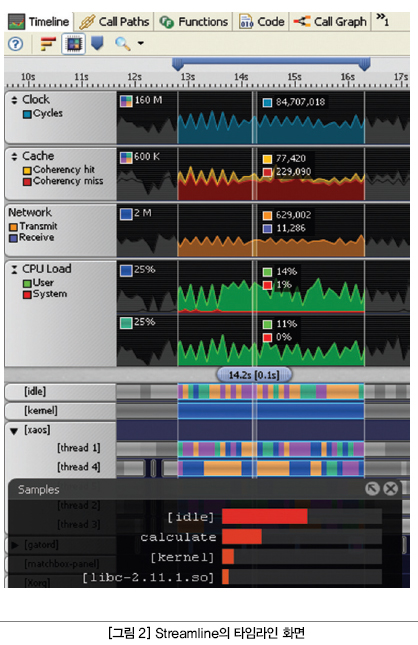
Perf와 같은 오픈 소스 툴과 ARM StreamlineTM 성능 분석기와 같은 상업적 툴은 샘플링 기반 프로파일러의 기능과 커널 트레이스 데이터 및 프로세서 성능 카운터를 결합하여, 애플리케이션이 커널과 시스템 레벨 리소스를 얼마나 활용하고 있는지를 알 수 있는 높은 수준의 가시성을 제공한다.
예를 들어, Streamline은 프로세서와 커널 카운터의 오버타임, 동기화 된 스레드, 프로세스 그리고 수집된 샘플을 단일한 타임라인에서 보여줄 수 있다. 이 정보들은 어떠한 애플리케이션이 캐시 메모리 혹은 네트워크 부하를 유발하는지를 재빠르게 찾아내는 데 사용될 수 있다.
인스트루먼테이션 기반 프로파일링
인스트루먼테이션은 성능 분석 방법의 그림들을 완성한다. 계측된 소프트웨어는 프로파일링 또는 코드 커버리지 리포트를 생성하기 위한 모든 함수-혹은 잠재적으로 모든 명령어-의 엔트리와 엑시트를 기록할 수 있다. 이는 소프트웨어 자체의 계측이나 자동적인 수정을 통해 달성된다.
샘플링 기반 프로파일링을 통한 인스트루먼테이션이 가진 이점은, 단지 샘플에 대해서가 아닌 모든 function call에 대한 정보를 제공해 준다는 것이다. 반면 이 방법은 매우 개입적이며 또한 상당한 속도저하를 일으킬 수 있다는 것이 단점이다.
안드로이드 트레이스뷰(Android TraceView) 소프트웨어는 시간 기반의 로그와 안드로이드 자바 애플리케이션에 대한 프로파일링 리포트를 생성하기 위해 인스트루먼테이션을 사용한다. 트레이스뷰의 주요 문제점은 각 자바코드의 라인 별 실행을 추적하기 위해서는, DalVik JIT 머신의 작동을 중지시켜야 한다는 점이다. 결과적으로 해석된 코드는 본래의 JIT(Just-in-time) 컴파일 코드보다 약 30배 정도는 느려질 수 있다.
각 작업에 적합한 툴의 사용
지금까지 설명한 모든 기법들은 전형적인 소프트웨어 설계 주기의 모든 단계에서 적용될 수 있지만, 각 단계별로 더 적합한 방법들이 있다.
명령어 트레이스는 대체로 커널과 드라이버 개발에 좀 더 유용하지만, 리눅스 애플리케이션과 안드로이드 네이티브 개발에는 사용이 제한적이며, 안드로이드 자바 애플리케이션 개발에는 사실상 전혀 사용되지 않는다.
커널 영역(Kernel space)에서의 성능 개선은 종종, 커널, 스레드 및 주변기기 간의 상호작용을 다루는 시간이 중요한 변수인(time-critical) 코드 핸들링에 있다. 이러한 코드의 개선을 위해서는 높은 정확도와 입도(granularity), 그리고 명령어 트레이스의 낮은 개입성이 요구된다.
둘째로, 커널 개발자는 코드에 관한 작업을 실행하기 위해서 전체 시스템에 대해 충분한 컨트롤을 가진다. 예를 들어, 개발자는 트레이스를 폭이 좁은 트레이스 포트를 통해 전송하기 위해 프로세서를 느리게 하거나, 빠른 주변장치를 위한 완전한 소프트웨어 스택을 손수 작성할 수 있다.
그러나 애플리케이션 영역에서 본다면, 개발자들은 명령어 트레이스의 정확도나 입도(granularity)가 필요하지 않은데, 약간의 소프트웨어 수정만으로 얻어진 성능 증가는, 개발자의 통제를 완전히 벗어난 무작위적 커널과 드라이버의 가동에 의해 쉽게 손실될 수 있기 때문이다.
애플리케이션 영역에서, 엔지니어링 효율성과 시스템 가시성(System visibility)은 완벽한 프로파일링 정보보다 훨씬 더 유용하다. 개발자는 어떤 코드 조각을 최적화할지 빠르게 찾아내고, 이벤트들 간의 시간을 정확하게 측정할 수 있어야 하지만, 코드의 5%의 속도 저하만 허용된다.
시스템 가시성은 커널과 애플리케이션 영역 모두에서 매우 중요한데, 이는 개발자들로 하여금 빠르게 문제점을 찾아내고 해결할 수 있도록 하기 때문이다. 캐시 메모리의 잘못된 사용, 프로세서와 주변장치의 미 종료, 비효율적인 파일 시스템에의 접근 혹은 스레드나 애플리케이션간의 데드락 등은 시스템과 관련된 성능 이슈에 해당되는 사례들이다.
시스템 관련된 이슈를 해결하는 것이, 수일에 걸쳐 단독의 애플리케이션을 위한 최적의 코드를 작성하는 것보다 10배 이상의 전체 시스템 성능을 증가시킬 가능성이 높다. 이러한 이유로 샘플링 기반 프로파일링과 커널 트레이스를 결합한 분석 툴은 리눅스 성능 분석, 특히 애플리케이션 레벨에서 계속해서 독보적으로 사용될 것이다.
인스트루먼테이션 기반 프로파일링은 높은 수준의 개입성으로 인해 가장 취약한 성능 분석 기법이다. 안드로이드 자바 애플리케이션의 최적화는 오픈 소스 툴보다는 수동으로 로깅을 할 때 성공할 확률이 더 크다.
뛰어난 성능의 안드로이드 시스템
대부분의 안드로이드 애플리케이션은 플랫폼 이식성(Platform portability)을 위해, 자바 레벨에서 개발된다. 아쉽게도 자바 코드의 성능은 JIT 컴파일러의 영향으로 인해 랜덤한 요소를 가지는데, 이는 성능 분석과 최적화를 어렵게 하는 요인이다.
어떠한 경우에도 안드로이드 애플리케이션이 빠르고 전력 효율적이 되도록 하는 유일한 방법은, 전체를 -혹은 적어도 일부분이라도- C/C++ 언어로 코드를 작성하는 것이다. 그 동안의 연구결과는 네이티브 애플리케이션이 동등한 자바 애플리케이션과 비교해서 5배에서 20배까지 빠르게 실행되는 것을 보여준다. 실제로 가장 인기 있는 안드로이드 게임, 비디오 및 오디오 애플리케이션은 C/C++언어로 작성됐다.
ARM 프로세서 기반의 시스템에서 작동하는 안드로이드 네이티브의 개발을 위해 안드로이드는 NDK(Native Development Kit)를 제공하며, ARM은 리눅스와 안드로이드 네이티브 개발을 위한 전문가용 소프트웨어 툴체인으로 DS-5를 제공한다.

<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



