



글 | 매트 손더스(Matt Saunders)마이크로컨트롤러 및 무선 제품 담당 수석 마케팅 매니저 실리콘랩스
임베디드 개발자들이 사용할 수 있는 CPU는 무수히 많지만, 각각의 CPU마다 특이성과 구조적 이점, 에너지 절약 기법이 다르다. 이글에서는 다양한 임베디드 CPU를 선택하는 데 널리 사용되는 ARM Cortex-M 시리즈를 중심으로 살펴본다.
ARM Cortex-M 아키텍처 시리즈는 살펴볼 수 있는 CPU 모델이 몇 가지 있으며 반도체 공급업체에서 제공하는 MCU 장치도 다양하다. Cortex M 시리즈 내에서 다양한 선택을 할 수 있다는 점은 분명 중요하다. 이유는 CPU 전력 소비는 CPU 아키텍처 그 자체만이 아니라 인터럽트 제어기, 메모리 인터페이스, 메모리 가속기, 저전력 모드 지능 주변 장치 등 그 주변의 지원 요소들을 통해 최소화할 수 있기 때문이다.
썸(Thumb)-2에 관해 알아야 할 모든 것
명확한 시작 지점이 아닐 수도 있겠지만, 전력 소비를 줄이기 위해 사용되는 기법인 명령어 세트부터 시작해보자. Cortex-M CPU는 모두 썸-2 명령어 세트를 사용한다. 32비트 ARM 명령어 세트와 16비트 썸 명령어 세트를 혼합한 것으로 순수 성능과 전체 코드 크기 모두에 유연한 솔루션을 제공한다. Cortex-M에서 구현되는 대표적인 썸-2 애플리케이션은 ARM 명령어에서 사용되는 코드와 비교해 범위가 25% 줄고 효율이(시간에 최적화된 경우) 90% 늘었다.
썸-2에는 기본 작동 시 사이클 계수를 줄이는 강력한 명령어들이 많이 포함되어 있다. 사이클 계수를 줄이면 CPU의 전력 소모가 매우 줄어든다. 예를 들어 16비트 증가를 보자(그림 1). 8비트 8051 기반의 CPU에서 이런 작동에는 48클록 사이클에 8바이트가 사용될 수 있다. C166 같은 16비트 코어의 경우 8클록 사이클에 8바이트 사용 범위에 해당한다.
반면에 썸-2를 사용하는 Cortex M3 코어를 사용한 경우 사이클은 하나 안에 플래시 메모리 2바이트만을 사용한다. Cortex M3은 같은 작업을 시행하는 데 필요한 클록 사이클과 플래시 메모리 사용량을 줄여 전력 소비를 줄인다. 따라서 이러한 최종 목표를 위해 플래시 메모리의 접근을 최소화해야 한다(잠재적으로 애플리케이션이 더 작은 플래시 메모리를 사용하도록 하고 전체적인 시스템 전력 소비 감소 포함). 썸-2 명령어 세트를 더 살펴볼 수도 있으나 다뤄야 할 중요한 문제들이 많이 있으므로 여기에서 줄인다.
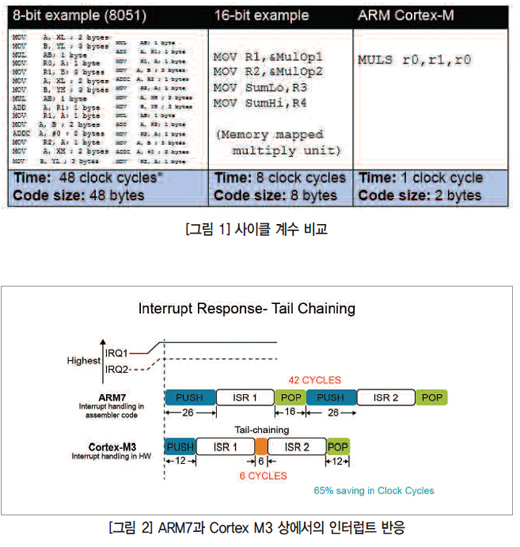
인터럽트 컨트롤러의 절전 기법
Cortex-M 아키텍처 내부의 인터럽트 컨트롤러(Nested Vectored Interrupt Controller, NVIC) 역시 CPU의 전력 소비를 감소시키는 역할을 한다. Cortex-M3 NVIC는 인터럽트 코드를 실행시키라는 요청에서 실제 인터럽트까지 12사이클밖에 걸리지 않는다. 기존의 ARM7-TDMI 상에서는 ‘최대’ 42사이클이 걸리는 것과 비교하면 효율이 높아졌고 CPU의 시간 낭비가 줄어든 것은 분명하다. 인터럽트 루틴으로의 진입이 빠르기도 하지만, NVIC는 하나의 인터럽트 루틴에서 다른 루틴으로의 이동도 훨씬 효율적으로 관리할 수 있다.
ARM7-TDMI 구현에서 인터럽트 루틴에서 주된 애플리케이션으로 이동했다가 다시 다음 인터럽트 루틴으로 이동하는 데에는 사이클이 걸릴 수밖에 없으며 단순한 ‘푸시-앤-팝(push-and-pop)’ 함수에서는 인터럽트 루틴 간에 최대 42사이클이 걸린다. Cortex M NVIC를 사용하면 ‘꼬리 물기(tail chaining)’라는 작업의 효율이 크게 향상된다. 이 방법은 필요한 정보를 다음 서비스 루틴에서 실행하기 위해 단순한 6개 사이클의 프로세스를 사용한다. 꼬리 물기에서는 하나의 푸시-앤-팝 사이클 전체를 돌지 않아도 인터럽트를 관리를 위한 클록 사이클에서 전력 소모가 65% 감소한다(그림 2 참조).
절전을 위한 메모리 고려
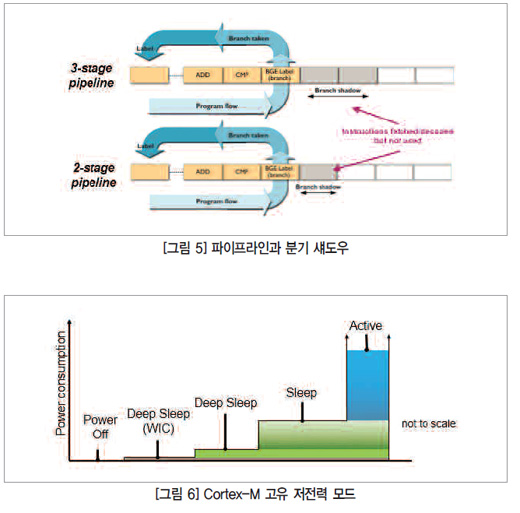
메모리 인터페이스와 메모리 가속기는 CPU의 전력 소모량에 큰 영향을 미칠 수 있다. 코드의 분기(branch)와 점프는 파이프라인을 깨끗이 비우는 효과가 있어 CPU에 명령어를 공급하며 이 경우 CPU는 파이프라인이 다시 채워지는 데 걸리는 여러 사이클 동안 정지해 있게 된다. Cortex-M3나 Cortex- M4 상에서 CPU는 3단계 파이프라인을 갖췄다.
이 경우 파이프라인을 비우면 파이프라인이 다시 채워지는 동안 CPU는 3사이클 동안 멈춰있다(플래시 메모리가 대기상태라면 더 오래 걸릴 수도 있다.). 이러한 정지 상태 동안 실제적인 작업은 사실상 일어나지 않지만, 전력은 소비된다. 지연을 줄이기 위해 Cortex M3과 M4 코어에는 Speculate Fetch 함수가 포함된다. 이 함수는 파이프라인에서 분기를 가져올 때 가능한 분기 타깃도 가져온다. 분기를 가져오면 Speculate Fetch를 사용해 정지 시간을 1사이클로 줄일 수 있다. 이 기능이 유용하기는 하지만 충분하지 않은 것은 분명하며 Cortex-M 장치 벤더들은 이러한 성능을 높이기 위해 자신들의 IP를 추가하기도 한다.
예를 들어 흔히 사용되는 ARM Cortex M 클래스 MCU에서 사용되는 명령어 캐시에 대한 여러 접근 방법을 생각해 보자. 단순한 명령어 캐시를 가진 MCU(예: 실리콘랩스의 EFM32)는 가장 최근에 실행시킨 명령어 중 128 x 32(512바이트)을 저장할 수 있다(요청받은 주소가 캐시에 있는지를 로직으로 확인).
EFM32의 참조 매뉴얼에 따르면 일반적인 애플리케이션에서 이러한 캐시의 적중률이 70%를 넘는데 이 경우 플래시 메모리의 접근 횟수가 줄고 코드 실행은 빨라져 전력 소비가 전체적으로 줄어든다. 반대로 64 x 128비트 버퍼를 갖춘 분기 캐시를 사용하는 ARM 기반 MCU는 처음의 명령어 몇 개만 저장할 수 있다(16비트나 32비트 명령어의 혼합 정도에 따라 분기당 최소 4개, 최대 8개).
따라서 분기 캐시를 구현하면 캐시를 이용해 분기나 점프 사이클 한 번 만에 파이프라인을 채울 수 있어 CPU 정지나 사이클 낭비를 막을 수 있다. 이러한 두 가지 캐시 기법은 모두 이러한 캐시 기능이 없는 동일 CPU와 비교했을 때 성능과 CPU 전력 소모 면에서 상당한 진전을 가져왔다(두 가지 캐시 유형 모두 플래시 메모리에 대한 접근 횟수를 최소화하고 MCU의 전력 소비를 전반적으로 줄일 수 있다.).
M0+ 코어 자세히 들여다보기
나노와트 단위 수준으로 전력에 민감한 애플리케이션의 경우 Cortex M0+ 코어가 적절한 선택일 수 있다. M0+는 폰 노이만 아키텍처를 기반으로(Cortex M3과 Cortex M4 코어는 하버트 아키텍처 기반) 전반적으로 낮은 전력 소비 수치에 대해 게이트 카운트가 작고 처리 능력이 최소 수준이다(큰 ARM 제품의 12.5 DMIPS/MHz에 반해 0.93 DMIPS/MHz에 불과).
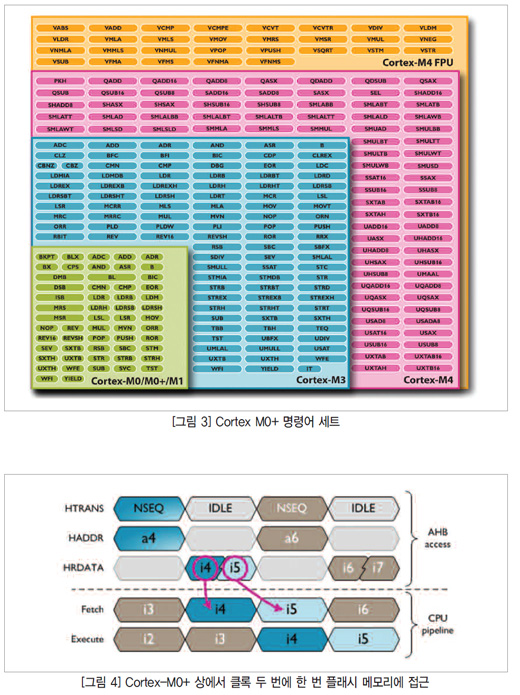
또한 썸-2 명령어 세트의 일부만을 사용한다(그림 3 참조). 이러한 명령어 대부분은 16비트 연산 부호(52 x 16비트 연산 부호와 7 x 32 연산 부호 데이터 연산은 모두 32비트)이므로 CPU 전력 소비를 줄이기 위해 특이한 옵션을 몇 가지 제공한다. 이러한 절전 옵션 중 하나가 플래시 메모리에 대한 접근 횟수를 줄이는 것이다.
명령어 세트가 대부분 16비트라는 것은 사이클 두 번에 한 번씩 플래시메모리에 접근하며(그림 4 참조) 접근 때마다 두 개의 명령어를 가져올 수 있다는 뜻이다. 이런 식으로 메모리의 32비트 한 단어 안에 명령어가 두 개 들어간다고 가정했을 때 명령어가 배열되지 않으면 Cortex M0+는 에너지를 절약하기 위해 버스 절반을 불능 상태로 만든다.
그뿐만 아니라 Cortex- M0+ 코어는 2단계 파이프라인으로 줄어들면 그에 따른 부산물로 전력을 절약할 수 있다. 파이프라인으로 된 프로세서에서 CPU가 현재 명령어를 실행하는 동안 이어지는 명령어를 가져온다. 프로그램이 분기하고 그에 따라 가져온 명령어를 사용하지 않는 경우 명령어를 가져오는 데 사용했던 에너지(분기 섀도우)는 낭비된다. 2단계 파이프라인에서는 이러한 분기 섀도우가 줄어들어 에너지가 절약될 수 있다(절약되는 전력량이 많지는 않다). 또한 파이프라인을 비우고 다시 채우는 경우 필요한 사이클이 하나 미만이다(그림 5 참조).
절전을 위해 GPIO 포트 사용하기
Cortex- M0+ 코어가 절전 기능을 제공하는 또 다른 방법은 고속 GPIO 포트를 통해서이다. Cortex-M3과 Cortex-M4 코어 상에서 비트나 GPIO 포트를 토글 하는 과정을 통해 32비트 레지스터를 ‘읽고 수정하고 쓸 수’ 있다. Cortex- M0+도 이러한 방식을 사용할 수 있으나 32비트 폭의 전용 I/O 포트를 사용해 한 번의 사이클로 GPIO에 접속할 수 있으므로 비트/핀의 효율적인 토글이 가능해진다. 주의할 점은 이 기능은 Cortex M0+의 선택적 기능이며 모든 벤더가 이런 유용한 GPIO 기능을 포함하지는 않는다.
CPU 재우기
CPU 전력 소비를 최소화하는 가장 효과적인 방법의 하나는 CPU 자체를 꺼 버리는 것이다. Cortex-M 아키텍처에는 슬립 모드가 여러 가지 있으며 선택한 슬립 모드에서의 전력 소비가 줄어들면 코드를 다시 실행시키기 위한 재시작 시간은 늘어난다(그림 6 참조). CPU가 인터럽트 서비스 루틴을 끝내면 추가 코드 없이 자동으로 슬립 모드로 들어가도록 할 수도 있다. 이 접근 방식을 통해 초저전력 애플리케이션에서 흔히 나타나는 그러한 작업에 드는 CPU의 사이클을 절약한다.
딥슬립 모드에서는 WIC(Wakeup Interrupt Controller, WIC)를 사용해 NVIC의 작업을 분담할 수도 있다. WIC를 사용하면 저전력 모드에서 CPU를 깨우기 위해 외부 인터럽트로 NVIC에 클록을 보낼 필요가 없다.
자동 주변장치로 CPU 작업 분담
자동 온칩 주변장치는 전력 소비를 줄이는 데 큰 도움이 될 수 있다. MCU 벤더 대부분은 주변장치 간에 자동 상호작용을 지원한다. 대표적인 예가 실리콘랩스의 EFM32 MCU 장치에서 사용되는 PRS(peripheral reflex system)이다. 주변장치 간의 자동 상호작용으로 인해 CPU가 슬립 모드인 동안 주변 장치 간에 상당히 복잡한 일련의 작업(데이터 전송이라기보다는 트리거)이 가능하다.
예를 들어 EFM32 MCU의 PRS 기능을 사용하는 경우 애플리케이션은 CPU가 슬립 모드인 저전력 상태일 때 온보드 비교회로는 임계값을 넘는 전압을 감지하고 타이머가 작동하도록 트리거한다. 타이머가 0이 되면 DAC가 출력을 시작하도록 트리거 하며 이 모든 작업은 CPU가 슬립 모드에 있는 동안 이뤄진다.
그러한 복잡한 상호작용이 자동으로 일어나므로 CPU 개입 없이 여러 가지 작업을 하는 것이 수월하다. 더욱이 센서 인터페이스나 펄스 계수기처럼 주변장치가 지능을 내장하는 경우 10펄스가 지날 때 등 미리 정해진 조건에서 CPU를 깨우도록 설정할 수 있다. 이러면 CPU가 그러한 특정 인터럽트로 깨어난다면 CPU는 어떠한 작업을 해야 하는지 정확히 알 수 있고 어떤 정보가 들어왔는지 알기 위해 계수기나 레지스터를 확인할 필요가 없어 사이클을 절약할 수 있으므로 다른 중요한 작업을 바로 시작할 수 있다.
맺는 글
이 글에서는 다양한 Cortex-M 장치 상에서 CPU 전력 소비를 줄일 수 있는 간단한 접근 방법을 다뤘다. 물론 이 외에도 장치를 생산하는 데 사용하는 프로세스 노드나 애플리케이션 코드를 저장하는 데 사용되는 메모리 기술 등 전력 소비에 영향을 미치는 다른 요인이 존재한다. 프로세스와 메모리 기술은 실행 시간 전력 소비와 저전력 모드에서의 전력 누설에 상당한 영향을 미칠 수 있으므로 임베디드 개발자가 전반적인 절전 전략을 짤 때 고려해야 하는 요인이다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>





